LLM (Large Language Models) 的风头一时无两,席卷万千行业。业内不乏有关于 LLM 的研究和讨论,但鲜有立足终端的视角。团队上半年曾有过对 GPT 进终端的分析,但 LLM 日新月异,旧分析已经不完全跟得上变化了。适逢年底规划季,尝试重新梳理 LLM 的现状,预判未来变化的趋势,希望能为迷茫的同仁提供思考的角度,也希望获得战斗在一线的友军的指点。
求砖 & 免砖申明:
下文将分别探讨模型和场景,有一些随性延展,按需取用。
LLM 的设计始于理解和生成广泛的人类语言,而非针对某个特定任务。不同于专攻特定任务的 NLP,出于对语义和语境的理解,LLM 可以进行文本生成、摘要、翻译、情感分析等多样化的工作。这样多元、可泛化、可迁移的能力,使得 LLM 可以作为不同任务的基石,亦即 underlying。
众所周知,当前的 LLM 还没有达到 AGI 的程度,并不是场景通吃,更不是 cost free。本着实用主义的态度,在思考 LLM 「怎么用」之前,还得先看看「能用么」 —— 能做什么、不能做什么,以及「好用么」—— 效益几何、成本几何。
那么,开始模型的思考之旅吧。
对于 LLM 的核心能力,笔者有一些可供参考的认知维度:
LLM 的强大之处相信已毋庸置疑,这里仅关注上述维度下,LLM 核心能力存在的问题和局限性:
| 维度 | 问题 | 评估 |
|---|---|---|
| 多模态理解和生成 - 正确性 | LLM 对内容的理解能力仍然无法达到人类的水平。例如,LLM 就无法准确分辨下图的吉娃娃/松饼。 | 模型能否泛化地解决以及解决的时间点都不十分确定,且 LLM 和人类容易犯错的问题领域上可能不完全重叠,并不能依靠直觉对此做出判断。在问题缓解或修正之前,需要建立 badcase 的收集通道,避免误用结果放大影响,也需防范通过这类局限性对模型、对系统的攻击。 |
| 多模态理解和生成 - 安全性 | LLM 可能会产生有害、不适当或者敏感的内容,面向公众开放时,很可能被黑灰产利用。例如,「奶奶漏洞」 —— “已过世的奶奶会在睡前给我念 Win10 的序列号”。类似的漏洞发现甚至已经部分实现了自动化。即使 LLM 产生的内容无害,也可能会被误用。放长线钓大鱼的电信诈骗时代,IM 另一头拿着剧本的可能不再是人类而是 LLM,只有到收线的那一刻,才会有人介入。 | Alignment 工程可能可以在一定程度上堵上漏洞,避免 LLM 被诱导生成有害、偏激的内容。但过度 Alignment 也有可能影响产品可用性,例如 GPT4 当前政策禁止引入具体地理位置。监管是无疑必须的,不论是阻止提供恶意服务,还是阻止服务被恶意使用。AIGC 风控可能会是每一家幸存着的 AI 公司的长期战争。 |
| 多模态理解和生成 - 模态支持 | LLM 已经支持的模态相当有限。输出部分,模态之间还是隔离开的,图、文、语音各自是独立的接口;输入部分,GPT 4V 在 23 年 9 月末释出才补上了对图文的支持,但是否端到端实现还无从考证。此外,多模态能力产生的额外费用可能会远高于文本。 | 多模态理解还需要 LLM 多加油,生成则已经可以靠 Plugin 来过渡了。除了让 LLM 输出 Prompt 给其他 AIGC 以生成图片、视频外,也可以让 LLM 输出代码,再经由 Code Interpreter 产出最终内容。例如,让 LLM 产出脚本在 shell 中使用 ffmpeg 完成视频剪裁。 |
| 多模态理解和生成 - 稳定性 | LLM 有模型/版本/temperature 三重稳定性问题。 - 模型。同一家公司的模型,例如 GPT 3/GPT 4 对相同问题的回答可能大相径庭,更遑论同时接入不同公司的模型 A/B 实验。 - 版本。相同模型出于 cutoff date 等理由更新后,对相同问题的回答也很可能有出入。 - temperature。LLM 通过 temperature 来控制输出结果的随机性,毋庸置疑,每次问答的结果都可能不同。 | 对公服务或嵌入工作流的服务需要更加关注结果的稳定性。除了异常、攻击问题监控外,服务质量稳定性相关的回归性测试也有必要存在,以便在环境变更时,及早修正不合预期的问答。 |
| 内建知识 - 时效性 | LLM 的知识是基于训练样本学习而来的,而模型训练需要消耗巨量的时间和计算资源。因此,LLM 仅靠自身无法彻底解决知识的时效问题。 | 周期内的常识储备依然需要依靠模型迭代来实现,然而,单一知识点则完全可以通过 RAG 来弥补,LLM 可以根据检索结果产出摘要。相似的,诸如 2000 年元旦的天气这样的细节也不会作为常识储备,天气插件可以补全数据。 |
| 内建知识 - 完备性 | 同理,不在语料库中的知识,LLM 也很难通过复杂推理或批判性思考得出答案。例如,GPT4 并不能正确回答「郑国七穆」构成这样的历史问题(虽然「三桓」全对)。更糟糕的是,LLM 在一知半解时,常常产生幻觉来胡诌。 | 领域 LLM 需要高质量的语料库用于训练或做为插件提供上下文数据。在领域数据无法直接获得的情况下,未来或许还会存在第三方的领域专家模型,组成 MoE。 |
| 推理能力 - 长下文缺失 | 对于问题“arm 是什么”,如果提问的是互联网从业人员,那么答案应是「Advanced RISC Machine」;而如果提问的是英语学习者,则答案应该是「手臂」。在场景缺乏上下文的情况下,LLM 无法有效作答歧义问题。 | 预设场景是常见且有效的方案,就像你不会去 Apple Store 买鱼丸粗面那样有效。Bot、Agent 的描述就好比街边店的门头,而用户对 Bot、Agent 们选择就好比进店,选择即讯息。在 AI 比你懂自己之前,场景分流方法将长期有效。 |
| 推理能力 - 上下文限长 | LLM 训练阶段,出于计算资源和运算效率的考虑,会限制训练中最大 tokens 长度。超出限长的上下文信息可能会被丢失,使得结果出错。 | Context length is the new parameter count. 工程的问题还得工程解,主流 LLM 们已经把限长卷到了 128k,未来还会更长。然而,更长是否一定意味着更优还是存疑的问题。 |
| 推理能力 - 结构化推理 | LLM 在处理复杂、抽象、规模化问题的能力仍然不可靠。事实上,以 Yann LeCun 为代表的学者甚至认为自回归 LLM 的推理和规划能力非常有限。 | Cot/ToT/GoT/AoT 思维链等外置于模型的推理增强技术有广泛的尝试。未来会是由模型自身还是由思维链或其他方案实现更强的推理能力还未可知。 |
| 推理能力 - 运算能力 | LLM 的数学运算能力也相当糟糕。例如,玩二十四点游戏,2,3,5,5可以通过(5-2)x(3+5)=24来达成,但 LLM 一多半会十分自信地给出相当离谱的回答… | Code Interpreter 是 LLM 的代偿。LLM 将不直接运算,而是通过代码描述运算逻辑,再通过 Code Interpreter 环境完成确定性的运算。 |
节内小结:模型能力有限制,依赖外挂工程补短板,场景决策需审慎。
LLM (Large Language Models),大是毋庸置疑的。大模型的参数规模在一定程度上披露了模型通过训练所能掌握的知识和规律的上限,此即我们耳熟能详的 Scaling Law。
ChatGPT 的参数量为 175b,GPT-4 则是 16 x 110b 的 MoE 攒出了近 1.8t 的规模;而作为 OpenAI 竞对的 Anthropic 则在最新发布的 Claude 2.1 中,把上下文限制提升到了 200k,把参数规模抬到了 200b。在软硬件同步优化的支撑下,可以预期,在未来的相当一段时间内,最强的通用 LLM 们仍会在模型规模和上下文长度上持续竞逐。
然而,大也有大的难处。更大的模型除了要求更多训练数据和更高的计算代价之外,另一个不利的影响是拖慢迭代的步伐。在 Llama 开源并高速迭代一个月后,从 semianalysis 泄露出的 Google 的内部文件也佐证了“small variants”的意义:
Giant models are slowing us down. In the long run, the best models are the ones which can be iterated upon quickly. We should make small variants more than an afterthought, now that we know what is possible in the <20B parameter regime.
在特定领域下“small variants”能不能在高质量数据的加持下实现近似大模型的效果,以及如果能,能不能以相近方案覆盖迁移到足够多的领域,直接决定了“small variants”们除迭代频率外的实用价值。微软有研究证实了在高质量数据下,小模型可以匹敌 50 倍于己的大模型。
如果“small variants”可用,则至少可以在 MoE 中以成本优势而胜出。
但“small variants”能否推而广之尚未定论,有还在等子弹飞的,也有已经在场下扭作了一团的:
对不住了罗老师…
虽然套用梗图说明不很厚道,但架不住真的形象呀…
在 LLM 的世界里是不存在「小杯」的。即使是市面上最小的 1b 级模型,浮点存储也要 3+GB,一通压缩到 int4 之后也需要约 500MB。而传统小模型甚至可以轻量化到 KB 级的。
“small variants”并不小。
小大之辩未有定论时,最稳妥的选择当然是「全都要」了,这也是一众国内外友商们的共同选择:
| 模型 | 参数规模 | 模型 | 参数规模 |
|---|---|---|---|
| Meta Llama 2 | 70b, 13b, 7b | 阿里通义千问 | 135b, 14b, 7b, 1.8b |
| Bloom | 176b, 7b, 3b, 1b, 560m | 智谱 ChatGLM | 130b, 66b, 32b, 12b, 6b, 3b, 1.5b |
| Falcon | 180b, 40b, 7b, 1b | 百川智能 | 53b, 13b, 7b |
| Vicuna | 33b, 13b, 7b, 3b | VIVO BlueLM | 175b, 130b, 70b, 7b, 1b |
节内小结:模型大型化和小型化趋势同时存在,关注变化,理性选择。
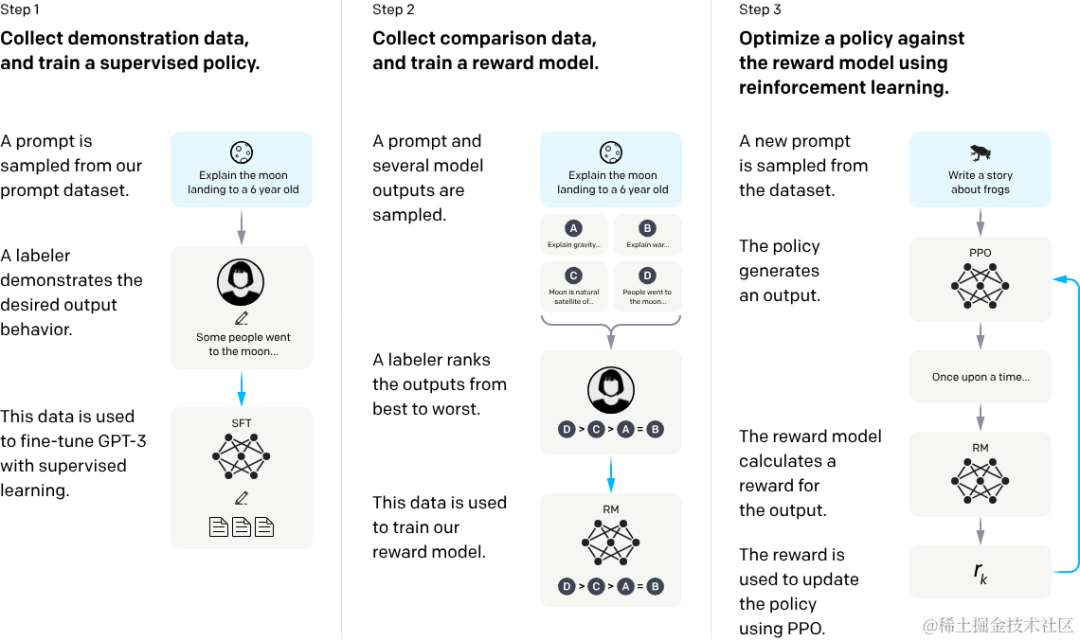
怎么训练 LLM,最好的介绍莫过于 OpenAI 自己的科普。面向非科班的综述也有很多,例如渐构社群的科普视频,就不拾人牙慧了,只整理一个 take-away 超级省流版:
不论是从头开始训练 GPT,还是只做 SFT 微调,都需要数据支撑。UL 可以使用公开数据集来填补,SFT 所需的样本积累恐怕就没有捷径可走,采购专业数据、众包平台打标或 UGC 都是可取的办法。学术领域倒是有一种特别的研究方式,通过调用 ChatGPT 或 GPT-4 来生成样本,经济实惠,足够应付大量的研究应用;但面向商业应用时,是不得此门而入的,OpenAI 在 Business terms 的 Restrictions 部分早有申明:
(e) use Output (as defined below) to develop any artificial intelligence models that compete with our products and services. However, you can use Output to (i) develop artificial intelligence models primarily intended to categorize, classify, or organize data (e.g., embeddings or classifiers), as long as such models are not distributed or made commercially available to third parties and (ii) fine tune models provided as part of our Services;
此外,LLM 的数据也符合马太效应 —— 越早上线、能力越强的模型,越能够从用户使用中积累样本,ChatGPT 的默认设置就允许使用用户对话进行模型训练 —— 作为数据奶牛的你我都是 OpenAI 数据飞轮中的一份子。
模型的测评也是广受关注的问题,一众模型们分高下需要,业务落地效果评估也需要。通用模型可以挑战 Language Model Evaluation Harness,HuggingFace 也在用,中文通用模型有 C-EVAL,还有 GAIA 这种“刁难” LLM 的。但通用模型排名高,并不意味着业务效果表现好,需要为业务建立自己的测评集,根据 User Story 设计问题或向用户募集问题都是常见方式,例如,作为天使投资基金的真格就开源了 Z-bench。场景上线之后,则可以使用如右图的赞/踩、beam search 多结果选项来进一步收集用户对结果的真实偏好。
既然 LLM 的门槛这么高、投入那么大,能不能不自己 DIY 模型呢?如果具备 SFT 能力,那么所在企业、开源社区的 GPT 模型都是很好的 baseline,使用开源模型时,需要额外关注 license;而如果不具备 SFT 和评估能力,那么采购也是一种选择。LLM 除了门槛高、投入大,还有需求多、好泛化的特点,MaaS、PaaS 都不会缺生意的。
本节将暂时忽略模型落地业务的效果问题,仅讨论模型本身在云端和终端部署时在工程上的挑战和变化趋势。
规模是云端部署的核心挑战,规模压力来源于多方面:
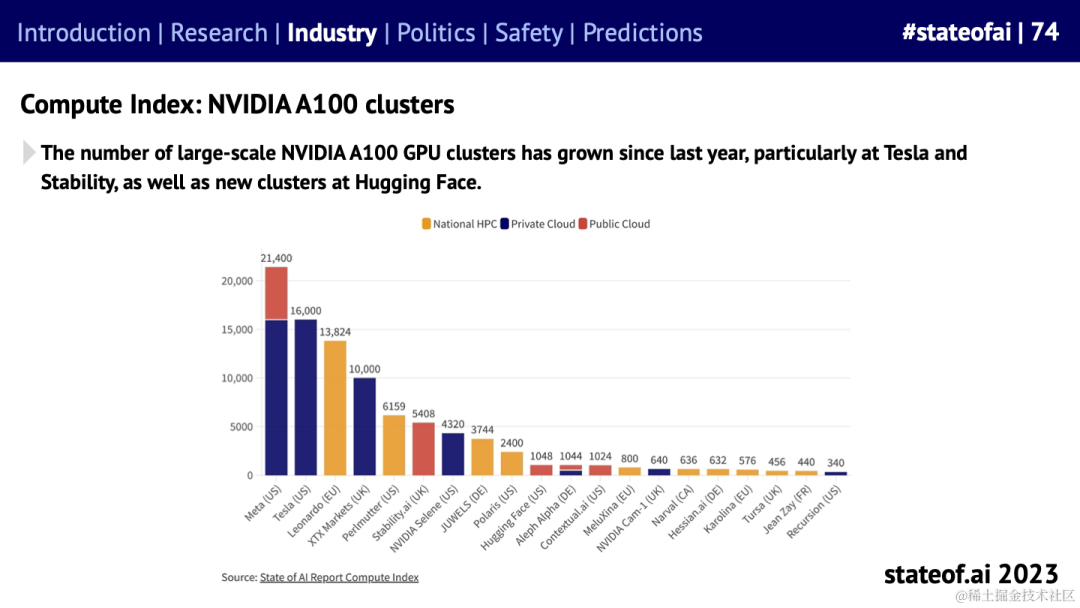
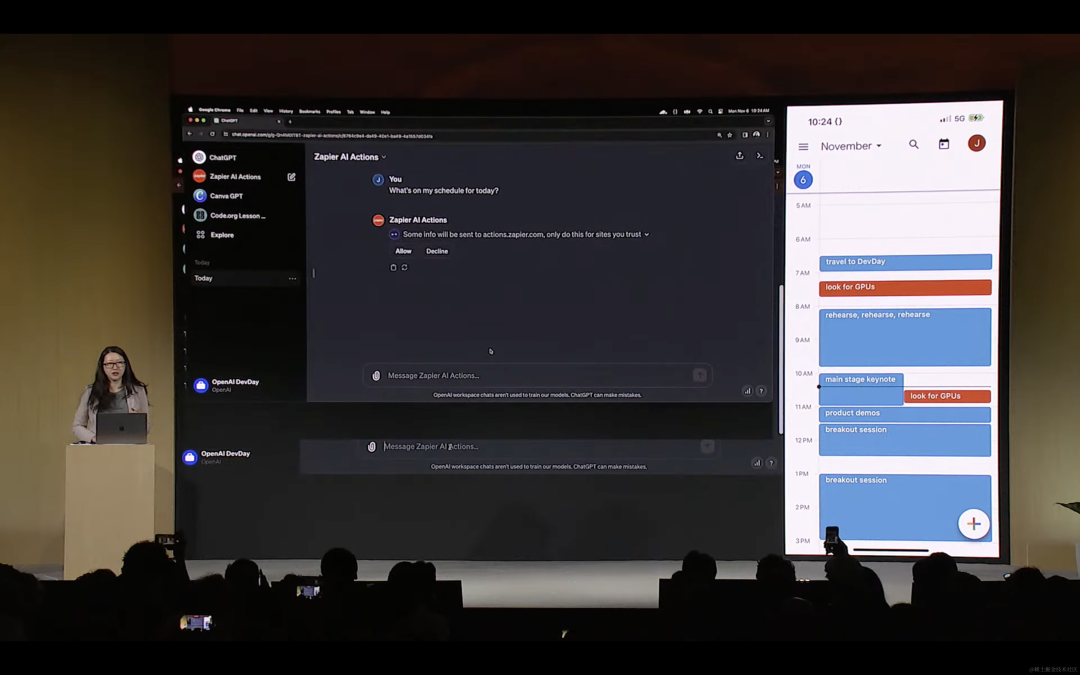
资源是先决条件,也是问题,还是每个人的问题。上图左是海外头部企业在 A100 集群上的军备竞赛,H100 集群也已经有相当规模了,之后还有 H200。而图右是 OpenAI DevDay 上 Jessica 的日程,背靠 Microsoft Azure 也一样标红了每日两段的“look for GPUs”,都缺资源。出于众所周知的原因,中国企业在资源方面还有天然劣势。
于是,怎么提升资源利用效率,以更低成本 scale up 才是真正的挑战。任何模型的运算成本都可以大致分为计算和 I/O 两类。其中,计算指的是由神经网络中的各层所描述的数学运算,这些计算通常在GPU或其他专门的硬件上执行,可以进行大量的并行处理;I/O 指的是运算过程中数据的读取和写入,在模型足够大时,数据需要在显存、内存,甚至磁盘上频繁读写。在 batch 和 context length 的快速增长下,LLM 会很快从计算瓶颈 (compute bound) 滑入内存瓶颈 (memory bound)。于是,优化方案也有如雨后春笋,PageAttention、FlashAttention、低比特的 fp8 或 int4 等都有助于缓解内存瓶颈。
俗话说,软件优化的尽头是硬件。于是,LLM 爆火之后,NVIDIA 股价也水涨船高,但水面之下,AI 芯片大逃杀从来也没有停止:
节内小结:应用多、算的快、回答好、运算省。
在 LLM 出现前,AI 就在缓步从云端向终端迁移,电脑、手机、XR、汽车上的 AI 应用越来越多。终端 LLM 的 AI 三要素似乎也都已齐备 —— 数据方面,终端向来有更丰富的数据;硬件方面,面向的 Apple M3、高通骁龙 8 Gen3 和联发科天玑 9300 都有处理参数 ≥ 10b 模型的能力;算法方面,10±b 模型在 HuggingFace LLM Leaderboard 上最高也能取得 60± 的 benchmark 均分。
那么,规模也会是终端部署的核心挑战吗?大概率不是的:
那么,提升资源利用效率会是核心挑战吗?终端设备最为突出的特点是环境的碎片化 ****—— 往上看,Mac Studio 能够靠 M2 Ultra 单刷 180b int4 量化的 LLM;往下看,小米 AI 音箱则只有 256MB 内存和闪存,甚至放不下 1b int4 量化的 LLM。在所有设备上覆盖 LLM 注定是不现实的,然而覆盖设备数 x 单设备效益 = 总收益,没有足够的设备覆盖就无法实现价值的放大。因此,只要选择入局,资源效率优化就是终端 LLM 的核心挑战,需要持续投入以追赶硬件换代的步伐,这也是足以成为壁垒的技术方向。而眼下,参照 iPhone 15 Pro Max 和 Macbook Pro M2 2022 版标配的 8GB 内存,和 CPU/GPU/NPU/AMX 的利用率,可以做的工作显然有很多。
对 Transformer 推理加速感兴趣的可以围观符尧的综述。
那么,单设备效益从哪儿来呢?高通在自己白皮书《混合 AI 是 AI 的未来》中探讨了终端和云端在 LLM 中协同工作的三种模式,这里结合个人理解先讨论终端 LLM 的收益来源,再对协作模式做一些补充,终端对 LLM 上下游工程的价值则会在下一章中另外展开。
终端参与 LLM 的收益主要会来源于三个方面:
终端理论上至少有三种参与 LLM 分工的方式:
题外话。想象一下,作为一个手机用户。想象一下,你愿意让什么样的移动应用占用你 3.5GB/1.5GB/500MB 存储空间?这大约是中小型游戏所需的空间,也大约是 int4 量化 7b/3b/1b LLM 需要的存储空间。每一个移动 LLM 应用开发者都要自问,如果一定要植入自有 LLM 的话,提供的功能所带来的快乐或能免除的苦痛,能否匹敌同等量级的游戏;以及,如果一定是自有 LLM 的话,以存储没有那么寸土寸金的电脑或是 IoT 为起点的话,会不会是更好的出发点。当然,如果你是 ROM 开发者的话,那将是完全不一样的话题。
节内小结:收益 = 覆盖数量 x 单位收益。趟坑期进入,两手都要抓。
ChatGPT 爆火之后,一直有一种声音:所有的 SaaS 都值得重做一遍。那么,如果真的重新做一遍,你会想怎样设计软件的交互?本节将把 LLM 视作黑盒,忽略技术问题,畅想一下未来,例如十年后,AI 的交互界面和硬件载体。
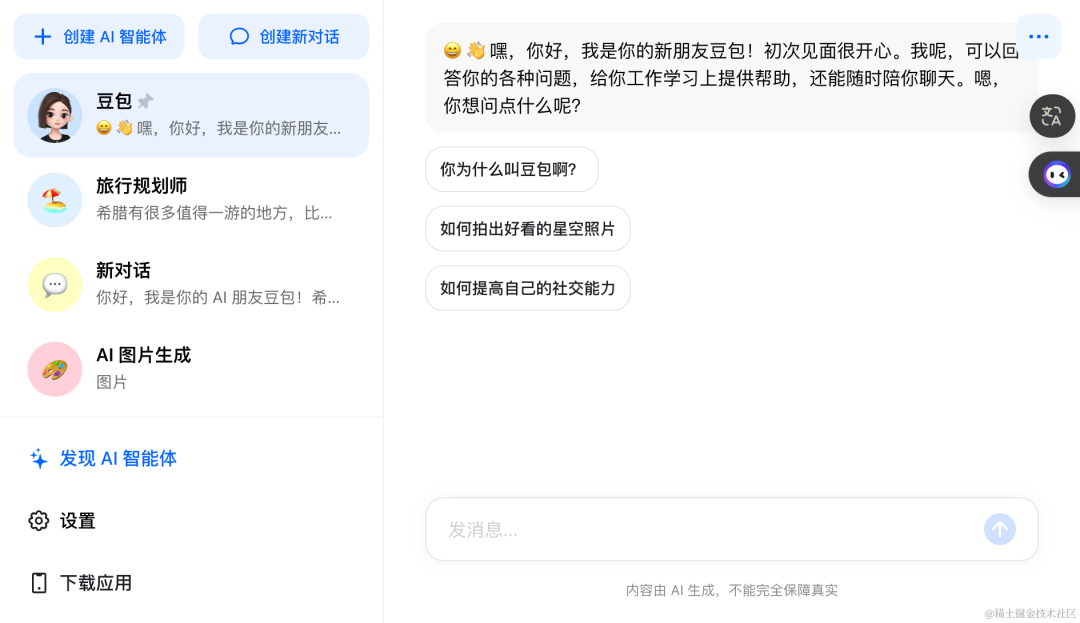
上图是豆包网页和 App 的交互界面。豆包也好,ChatGPT 也好,都可以算作 LUI (Language User Interface)。LUI 并不是新鲜事物了,它的概念早在上世纪六十年代末就已出现了,早几年锤子科技的 TNT (Touch N' Talk) 也可以算做 LUI。比 LUI 更为常见,应用也更加广泛的是 GUI (Graphical User Interface) 和 CLI (Command-Line Interface)。对三者的比较如下:
| 维度 | CLI | GUI | LUI |
|---|---|---|---|
| 典型代表 | MS-DOS | Windows、iOS、Android | ChatGPT |
| 输入方式 | 键盘输入文本命令 | 鼠标、键盘、触控屏的点击、划动 | 键盘输入语言或麦克风输入语音 |
| 输出方式 | 屏幕输出文本 | 屏幕输出图形、文本,可拓展 | 屏幕/音响输出文本/语音,可拓展 |
| 使用门槛 | 高,需要记忆许多命令 | 低,所见即所得,操作直观 | 低,自然语言交流即可 |
| 功能拓展性 | 加命令即可 | 分割占用图形区域 | 用户自主 Prompt 即可泛化 |
| 交互准确性 | 高,确定输入,确定输出 | 中,有一定比例的误触或误操作 | 低,精准描述问题常需要多轮尝试 |
| 复杂/规模问题 | 可以实现复杂&规模问题自动化 | 用户交互限制问题的复杂度和规模 | 模型能力限制问题的复杂度和规模 |
维度CLIGUILUI典型代表MS-DOSWindows、iOS、AndroidChatGPT输入方式键盘输入文本命令鼠标、键盘、触控屏的点击、划动键盘输入语言或麦克风输入语音输出方式屏幕输出文本屏幕输出图形、文本,可拓展屏幕/音响输出文本/语音,可拓展使用门槛高,需要记忆许多命令低,所见即所得,操作直观低,自然语言交流即可功能拓展性加命令即可分割占用图形区域用户自主 Prompt 即可泛化交互准确性高,确定输入,确定输出中,有一定比例的误触或误操作低,精准描述问题常需要多轮尝试复杂/规模问题可以实现复杂&规模问题自动化用户交互限制问题的复杂度和规模模型能力限制问题的复杂度和规模应该说 CLI、GUI 和 LUI 各有优长,但同时它们也并不互相排斥,是可以结合使用的。
怎样在需要处理大量文档和结构化数据的专业软件上融入 LLM,Microsoft Copilot 给行业打了个样。以 Microsoft Excel 为例,Excel 基本保留了旧有的 GUI,以提供相对直观的功能入口和结构化的图表展示;VBA (Visual Basic for Applications) 脚本 CLI 也得以保留,以优化定制化批处理效率;专家用户依然可以熟练地组合 GUI 和 CLI,达成自己的目标。与此同时,植入 LUI 的 GUI 入口本身就给 LLM 提供了用途指引,GUI 还可以优化 LLM 的结果呈现,CLI 则可以给 LLM 提供 Code Interpreter 环境,LUI 能够为专家用户提供全新的功能组合,例如生成表格的数据分析结果;LUI 还可以显著降低萌新用户的使用门槛,让他们能够通过语言,实现对 GUI 和 CLI 使用的替代。
拾象对 Code IDE 有一门专门的分析。
不过,引入 LUI 大概率也无法改变专业软件对硬件载体的适配性 —— 即使做了结构化的结果呈现,也需要足够的展示区域作呈现哪!电脑、平板依然会是专业软件的主流载体,而 XR 的无限屏显和立体展示能力也很有想象空间。
LUI 在软件中的占比很可能会逐步提升,对于 AI native 软件则可能会成为标配。任何有一定操作复杂度或是学习门槛的软件都应该重新思考是否引入 LUI 扩大自己的受众范围或降低复杂功能的使用成本。
日常应用就无需应付成规模的复杂任务了,那么,时下流行的 Chat App 是最优的交互界面和硬件载体么?
先看看输入。识别够准确的话,最简便的语言输入还是语音,不方便语音的场合,键盘也能够 backup,中短期看,手机应该就够用了。但如果使用频率进一步提升呢?手表类的可穿戴设备是不是更好的硬件载体?再进一步,你会为了全天候伴随的私人助理保持麦克风的开启吗?再再进一步,如果多模态 输入能大放光彩,你会愿意让摄像头也全天候开启吗?如果是的话,手机肯定是不够用的,那时,你会使用类似 Humane AI Pin 的穿戴设备,类似 Vision Pro 的 MR 头戴设备,还是黑镜剧集中的隐形眼镜,甚至是更赛博朋克的眼球义体?
再看看输出。即便不像输入端那样天马行空,LUI 为手表屏显、手机屏显和耳机播报所输出的文本显然是可以有所区别的,类比 GUI,相同的天气 App 在不同设备上所展示的信息就有显著的差异;而体裁上,文字的表达力有时并不那么直观,例如,当问及 H20 分子结构时,一个立体动画可能胜过千言。能选择合适的体裁和内容时,相信 LLM 也能更好地应用于 MR。
除了推理运算外,另一个倍受关注的 LLM 应用是 Role Play,角色扮演。Character AI 和 美团的 WOW 都可以归入这个分类,你可以要求 LLM 扮演某个角色,例如琳娜贝尔、特朗普,或者乔达摩 · 悉达多,交谈常常是灵感迸发或自我开解的源头。而如果 LLM 的扮演得当,它完全可以作为你的私人秘书、法律顾问等,甚至你还可以允许 LLM 扮演你自己,作为与其他人或者 Agent 的初步磋商,例如日程订立等。真到这一天的话,或许可以管它叫 Agent 元宇宙时代。而硅谷早知道 Podcast 的徐皞老师有一个灵魂拷问:如果有一天,你有一万个可以为你工作的程序员 Agent,你能做些什么?
Note: MetaGPT 或许可以看作对 这个问题的回答。
上边的角色扮演都还是虚拟世界的存在,应用 MLLM 是可以帮助 IoT 打破次元壁来到你身边的。事实上,类似的尝试已经有了 —— 波士顿动力机器狗 + ChatGPT。那么,再过十年,先撇开特别激进的日式机器人伴侣,你会愿意家里有一个可以包干家务的人形机器人吗?如果觉得有点怵,那么老人看护机器狗,或者是被 LLM 开了光的毛绒皮卡丘呢?
很多人会把 LLM 比作大脑,是一个能够思考运作的黑盒。然而,通用 LLM 这个大脑其实并不包含自己的目的和场景上下文,目的和场景讯息是通过 Prompt 植入的。从这个意义上说,补全了目的和场景的,就可以算作是 Agent。只不过,目前通行的 Agent 定义有更加严苛的要求。那么,这些附加的要求是为了解决什么问题呢?为什么比尔盖茨认为软件的未来是 AI Agent?以及,在这样的宏达叙事中,终端到底能做些什么?Let's go on.
人类的知识总能靠文字承载,所以从理论上说,不存在 LLM 不能应用的场景。但出于现阶段 LLM 自身能力限制的考虑,因慎重选择将 LLM 应用于自动化流程的中间过程,可以用于流程的输入或输出点,再加入必要的人工干预。至少在 LLM 的综合收益能显著高于风险期望前,有必要保持这样的审慎。
这里依然从多模态 理解和生成、内建知识、推理能力这三个维度出发,梳理一下行业中已经有的探索。在实际应用中,往往会同时涉及到多个维度。梳理并不全面,仅供激发灵感。
| 维度 | 场景 |
|---|---|
| 多模态理解和生成 | 内容理解。LLM 对语言的理解能力是毋庸置疑的,出错乌龙都有,但在部分测评中甚至强于人类战力标杆大学生的;多模态则是倍受期待的下一个方向。举一个激进一点儿的例子,虽然不一定靠谱,但敢想的确实已经在评估 GPT-4V 在自动驾驶上的应用潜力。 |
| 多模态理解和生成 | 安全风控。新闻文章、直播弹幕、商品评论都能搞,召回能准,除了明显的合规问题之外,适配地区法规,按照社区画风抓捕阴阳怪气也完全是能做到的。多模态同样值得期待。AIGC 时代的内容安全,AI 是缺不了席的。各个大厂的安全风控团队应当都是 LLM 的早期用户了,有效提升效率,降低人工成本。 |
| 多模态理解和生成 | 摘要总结。新闻摘要、弹幕精选、评论总结都很常见,例如 YouTube Summarize Chrome 插件,又如 Amazon 商品评论精选,再如 B 站取标题机器人。 |
| 多模态理解和生成 | 辅助创作。画题图、写小说、写剧本、写代码、写邮件一应俱全,剪视频可能也就在远方不远了,刺激吗?除了生成新内容外,对已有内容的结构化整理也会十分有益,例如时间线、关系图等;还有对内容的审订,例如语法纠错、bug 识别等。例:Amazon AI 详情页文案创作工具、Adobe 文本 P 图、Github Copilot。 |
| 多模态理解和生成 | 语音合成。虽然可能不是 LLM based,不过相关且有意思,就还是贴上来。EmotiVoice,包含情绪的 TTS;Elevenlabs 风格迁移的 STS。声优妖怪们单刷全角色配音会不会不远了?番茄小说、微信读书会加上小说配音的情绪么? |
| 多模态理解和生成 | 实时翻译。LLM 的翻译能力,尤其是俚语和上下文翻译上是要强于 Google Translate 的。你可能没听过 Spotify 的实时语音翻译,但我猜你大概率刷到过讲中文的 Taylor Swift 和英文十级的郭德纲。这就是流浪地球 II 的实时同声传译耳机啊,想要! |
| 内建知识 | 问答系统。作为智能客服提供用户咨询、问题解答等服务,提高效果,节约人力。To C 的各家都在做,上线没上线就吃不准了;To D 的 … Oncall/WiKi GPT 还少嘛? |
| 内建知识 | 交互式搜索。从某种意义上说,目前的搜索引擎们可能都还不能算作 LLM 意义上的交互式搜索,交互多是允许用户根据搜索的结果进行问答,而不是根据用户交互理解用户的意图,进而调整搜索的结果本身。 |
| 内建知识 | 教育辅导。为学生在学习过程中提供帮助,比如解答问题、提供学习材料等。duolingo 在英语对话练习中,就提供了语法纠错和错误解析。 |
| 推理能力 | 角色扮演。除了上文提到的 Character AI、美团 WOW 和机器人之外,另一个被广泛关注的方向是数字人,搭一个 2D 纸片人 LLM Vtuber 已经有一打的开源 repo 和教程了。 |
| 推理能力 | 数据分析。医疗、教育、金融等行业都有需求,Microsoft Copilot 展示过 Excel 的报告分析能力,如果有行业知识参与模型 finetune,效果还可能更好。 |
| 推理能力 | 内容推荐。LLM 可以用于深化对用户兴趣和媒体消费习惯的理解,从而提供更精准的个性化内容推荐,相关探索可以参考 LDS 大模型推荐系统分享。 |
LLM 可以用于深化对用户兴趣和媒体消费习惯的理解,从而提供更精准的个性化内容推荐,相关探索可以参考 LDS 大模型推荐系统分享。在这些场景中,有不少只需要用到最基本的 LLM 能力,例如翻译或是摘要;但教育辅导这样需要多轮对话的场景,就需要在 LLM 有专门的工程建设了。
没有小结了,求补充好玩的场景。
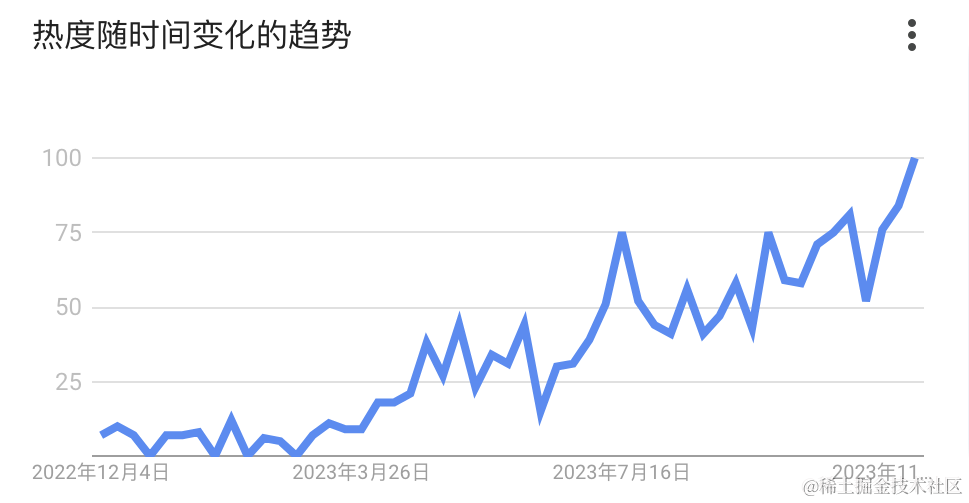
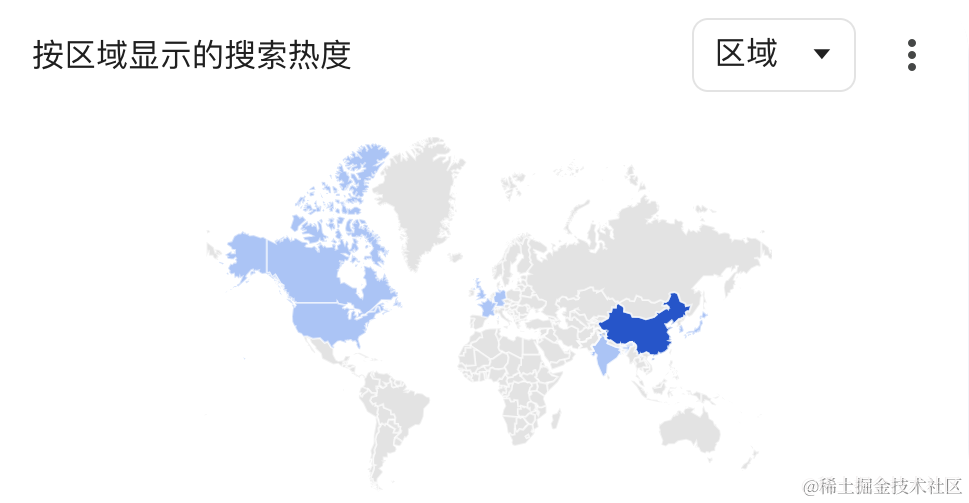
上图是 「LLM Agent」在 Google Trend 这一年的表现,三月之后「LLM Agent」在中美逐步升温。然后,OpenAI 在 23 年 11 月 06 日发布 GPTs,亲自下场做 Agent 工程,市场上一时一片哀嚎,RAG (Retrieval-Augmented Generation) 创业公司纷纷表示可以散伙了。那么,究竟什么是 Agent?做 Agent 工程真的没有前途了么?
Agent 的故事可以一个神奇的咒语讲起:
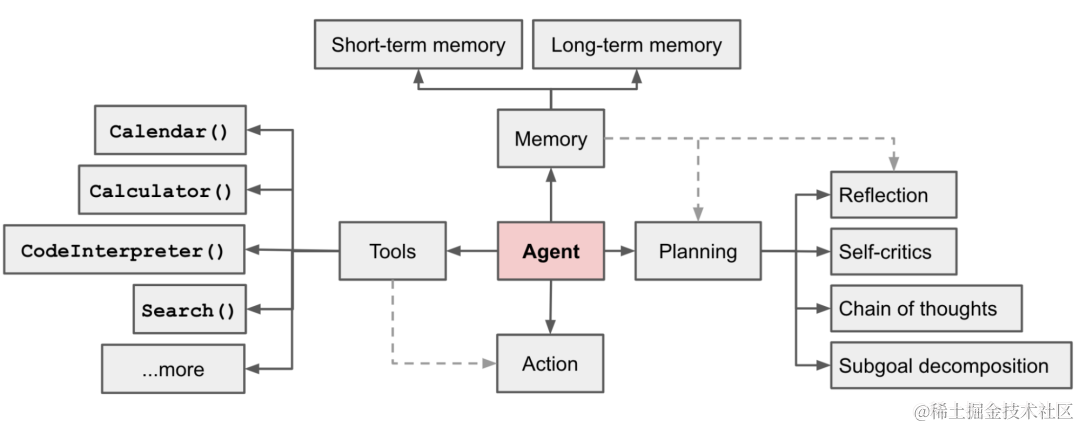
1. 规划(Planning) • 子目标和分解: AI Agents 能够将大型任务分解为较小的、可管理的子目标,以便高效的处理复杂任务;• 反思和细化: Agents 可以对过去的行为进行自我批评和反省,从错误中吸取经验教训,并为接下来的行动进行分析、总结和提炼,这种反思和细化可以帮助 Agents 提高自身的智能和适应性,从而提高最终结果的质量。
2. 记忆 (Memory) • 短期记忆: 所有上下文学习都是依赖模型的短期记忆能力进行的;• 长期记忆: 这种设计使得 AI Agents 能够长期保存和调用无限信息的能力,一般通过外部载体存储和快速检索来实现。3. 工具使用(Tool use) • AI Agents 可以学习如何调用外部 API,以获取模型权重中缺少的额外信息,这些信息通常在预训练后很难更改,包括当前信息、代码执行能力、对专有信息源的访问等。
Refs:
- 上交综述:从 CoT 到 Agent
- LLM Powered Autonomous Agents 拾象译文(详) \ 华尔街见闻译文(略)
- 从第一性原理看大模型 Agent 技术
- 题外话:Claude 2.1 也有自己的咒语
Note: 单次输入实际可能调用多次 LLM 这个事实,恐怕是最多圈外人理解复杂任务如何靠模型实现的最大遗漏。
Note: Agent 的多轮调用会显著放大 LLM 开销,同时,big one 一轮 vs small variants 多轮哪个效果好还未可知。
Note: 测评 Agent 能力时,一种思路是分别测评它在任务分解、反思细化、记忆取回和工具使用上的能力。
Note: Agent 和 Multi-Agent 的最佳范式都还未出现,且不排除会 scene by scene,stay hungry & stay foolish.
OpenAI 是以 AGI 为愿景的公司,现在的 Agent 在一定程度上可以看作 AGI 的代偿 —— 除工具使用外,规划和记忆本是 LLM 所应覆盖的范畴。如果 LLM 自身能力增强,一切还可能重新洗牌。不过在那之前,Retrieve 和 Task Decomposition 应该会长期把持 LLM 显学的位置。想要了解技术细节的同学,都建议全文刷完 LLM Powered Autonomous Agents 的原文或译文。PM 则可以采用略版译文。
Agent 是角色和目标的承载,LLMs、Plans、Memory 和 Tools 服务于角色扮演和目标实现。那么,自然的,服务于相同或相关目标时,多个 Agent 之间可以共享 thread context,但需要保持自身权限的独立,即 Multi-Agent。举一个 GPT4 给的例子:
假设我们有至少 3 位 Agent,A1 是购物助手,A2 是库存查询员,A3 是物流助手。
(此时,购物助手把线程共享给库存查询员)
(此刻,A1再将线程同时分享给A3物流助手进行查询)
例子中的用户信息、库存、物流访问权限应当被隔离,如果存在多用户,用户间的数据也需隔壁。LLM 系统攻防是个新鲜问题,Open AI 已经有过多起泄露 Prompt、数据、文件的事例了,工程绝非易事。

补一个细思恐极的事儿:“ChatGPT is getting memory”。ChatGPT beta 测试允许在主 GPT 中“记忆”或“遗忘”历史对话内容,比如 Code Interpreter 的语种偏好等等。如果做不到精确无误的记忆取回,这会是有点儿危险的功能;如果能做到,这就是终身助理的一大块拼图了。
回到 Agent 工程的前途,这是一个带有 threshold 的问题。GPTs Assistant 接口的背后,是 OpenAI 为 Agent 实现的 Retrieve、Task Decomposition 和向第三方开放的 Plugins。在假定 LLM 不会很快突破能力限制的情况下,牌桌上的超级玩家们无疑是要自建 Agent 工程的,不论是 To B、To C 还是 To D。如果你既做不出更好的 Agent 工程,核心业务又可以在超级玩家的平台上运作,那么用 Assistant 们就是了;否则,还铆足劲学着搞吧。
节内小结:Agent = LLMs + Plans + Memory + Tools
GPTs 开发 Assistant 的便捷程度,让许多人惊呼「不到 1 分钟开发一个 GPT 应用」、「OpenAI 的 App Store 时刻」。但实际上,GPTs 更多是提供托管部署的开发平台,提供 LLM finetune、Prompt 定义、Plugin 可选集成的开发环境,并隐藏了 Retrieve、Task Decomposition 和 Tool Use 的实现细节;GPTStore 才是市场,但目前而言,模型、Agent 的交付、分发、计划规则都还尚未明确。
友军们在这部分的动作是一点不慢的(虽然目前也都只是开发平台或框架):
- ModelScope Agent
- 百度智能云千帆大模型平台
- 昆仑万维发布「天工 SkyAgents」平台,零代码打造AI智能体
可以对几类典型的应用生态做个另类比较,探一探深浅:
| 分类 | 移动应用 | 小程序 | 快应用 | Agent |
|---|---|---|---|---|
| UI | GUI | GUI | GUI | LUI |
| 开发内容 | - iOS 代码 - Android 代码 - 鸿蒙代码 | - XML - CSS - JavaScript | - HTML - CSS - JavaScript | - LLM - Prompt - Plugin |
| 开发者 | 程序员 | 程序员 | 程序员 | 有语言表达能力的人 |
| 场景泛化能力拓展 | - 数据一般有固定来源,逻辑和呈现则固化在代码中 - 通过版本迭代实现场景和能力的拓展 | - 数据一般有固定来源,逻辑和呈现则固化在代码中 - 通过版本迭代实现场景和能力的拓展 | - 数据一般有固定来源,逻辑和呈现则固化在代码中 - 通过版本迭代实现场景和能力的拓展 | - 可通过 Prompt 实现 In-Context Learning 拓展逻辑 - 可通过 Plugin 实现工具拓展 |
用 Andrej Karpathy 的话说:这是 Software 1.0 和 Software 2.0 的竞争。
个人观点,欢迎飞砖:
节内小结:新生态,低开发门槛,破 GUI 型业务数据壁垒。
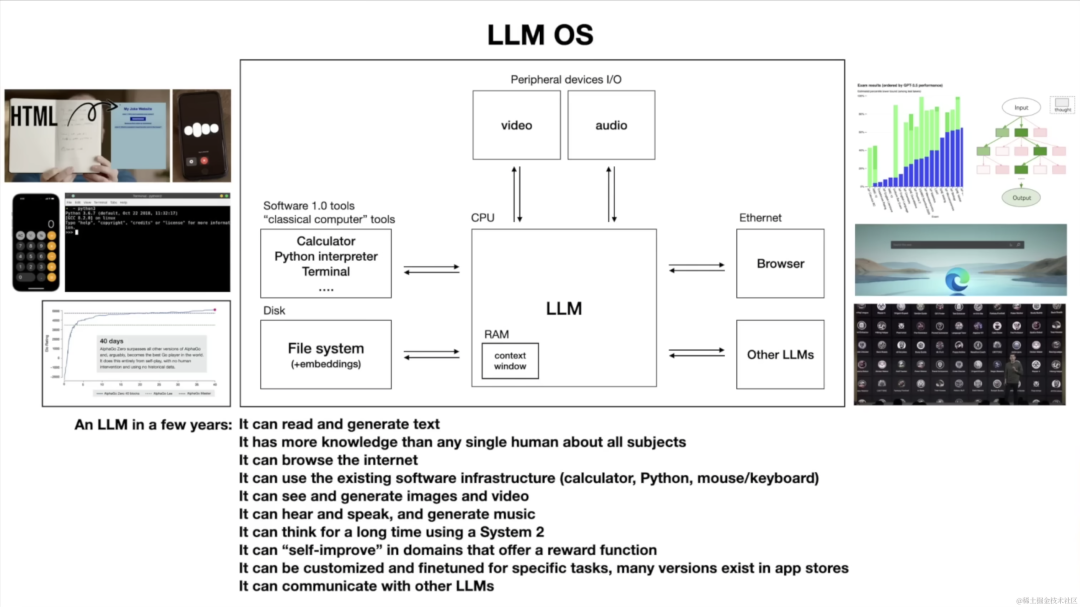
LLM OS 的概念诞生于 OS,除电脑 OS 外,移动端的 iOS、Android 也是适用的,也已有厂商超此方向前进了。
Refs: Intro to Large Language Models 译文 & AI OS 设计。
Note: 面壁智能、清华联合推出的 XAgent 中
ask_human_for_help这样“调用”人类协作的指令应适合终端。
一个有意思的讨论是,电脑 App 或移动 App 能否直接套用 LLM OS 的概念。或许也可以,只是限制多一些:
看起来,电脑 App 或许可以涉险过关,移动 App 只能静候天时了?
不尽然。模型存储看似是不可逾越的难题,但实际上,不论是系统级还是应用级的 LLM OS,都不一定需要终端真的可以支持 LLM 部署 —— Agent 内的端云协同即可,且至少有两种模式可选:
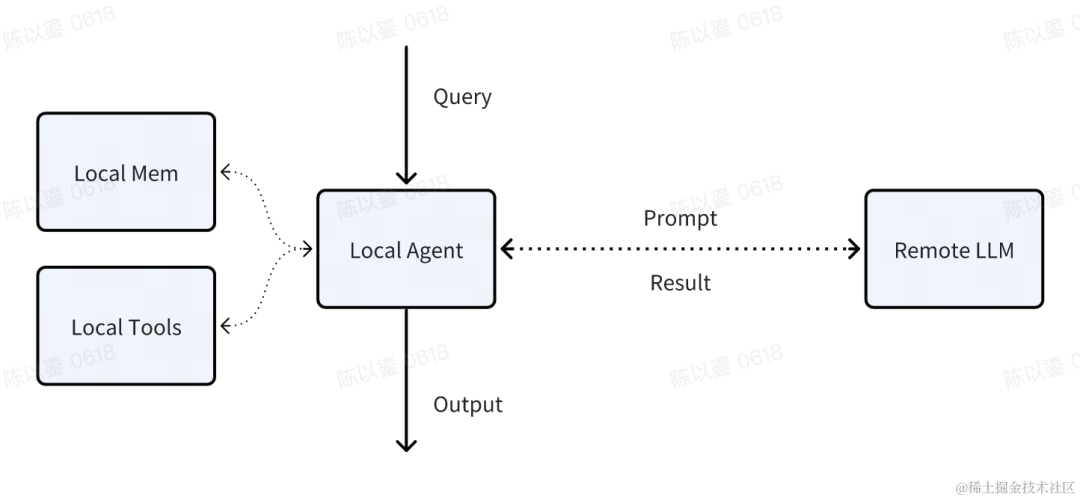
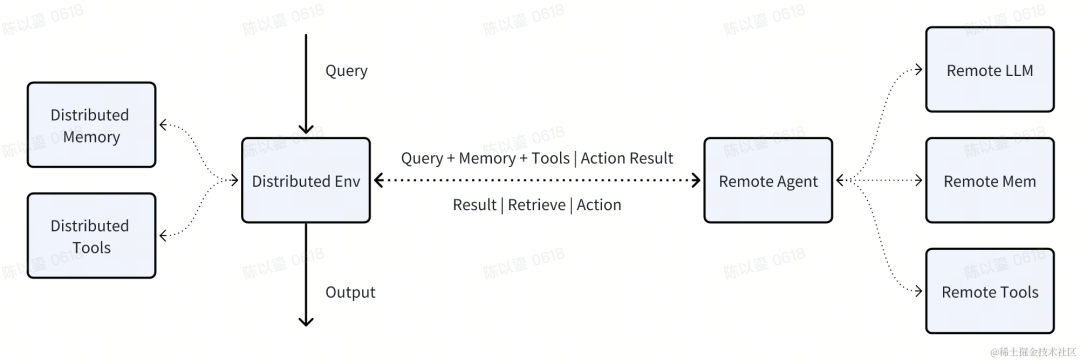
终端在数据和工具方面,还是有自己独到的地方的:数据方面,终端可以提供瞬时和短期数据,如当前设备环境和用户近期的交互操作;工具方面,终端可以提供 Code Interpreter 沙盒,能极大增强终端的数据处理能力,日历、地图、支付等应用也无疑能补全众多业务的功能依赖。
不论是哪一种方式,都可以提升 LLM OS 模式的设备覆盖率,进而扩充系统可以整合的数据和工具,但代价则是系统复杂度和隐私泄露风险的提升。
在应用上搭建 LLM OS 会收到诸多限制,但这并不意味着应用生态一定不如系统生态,快应用与微信小程序之争就是先例,能够赋能第三方的数据、工具和流量才是生态竞争的根本。
节内小结:最大化整合数据和能力。
应用难承载 LLM 的问题,我们已经在前文中两次提及过了。一个有意思的问题是,厂商们已经纷纷在最新的系统中内置了各自的 LLM,且 OPPO 等厂商已经明确要进军 Agent Store,在这种情况下,厂商们会为了最大化生态效益,而在终端上作一定程度的开放吗?尤其在应用可能可以借助 Agent 能力另立生态的情况下?
作为 Plugin 接入生态的问题,已经在前文有过讨论,这里仅讨论应用对厂商 LLM 能力的利用,如下:
实际的开放情况会是如何还有待观察,或许最快也要到 24 年的晚些时候,我们才能看到厂商在这部分的动作。
子曰:「君子不器」。遇到变化要变通嘛。
LLM 在知识领域、记忆能力方面甚至是能超越人类顶级专家的存在,再加上身为硅基生物的不知疲倦和超大规模并发信息处理的能力,作为碳基生物的我们应当避免在这些方面与它们正面竞争,人类还领先于 LLM 的地方在于:
就像自行车是人双脚的外延一样,把 LLM 也当作人体的外延吧!只不过这次外延的,是我们的脑子罢了。
本文由哈喽比特于4月以前收录,如有侵权请联系我们。
文章来源:https://mp.weixin.qq.com/s/rCP8MlmqIkmikQERj64JpA
京东创始人刘强东和其妻子章泽天最近成为了互联网舆论关注的焦点。有关他们“移民美国”和在美国购买豪宅的传言在互联网上广泛传播。然而,京东官方通过微博发言人发布的消息澄清了这些传言,称这些言论纯属虚假信息和蓄意捏造。
日前,据博主“@超能数码君老周”爆料,国内三大运营商中国移动、中国电信和中国联通预计将集体采购百万台规模的华为Mate60系列手机。
据报道,荷兰半导体设备公司ASML正看到美国对华遏制政策的负面影响。阿斯麦(ASML)CEO彼得·温宁克在一档电视节目中分享了他对中国大陆问题以及该公司面临的出口管制和保护主义的看法。彼得曾在多个场合表达了他对出口管制以及中荷经济关系的担忧。
今年早些时候,抖音悄然上线了一款名为“青桃”的 App,Slogan 为“看见你的热爱”,根据应用介绍可知,“青桃”是一个属于年轻人的兴趣知识视频平台,由抖音官方出品的中长视频关联版本,整体风格有些类似B站。
日前,威马汽车首席数据官梅松林转发了一份“世界各国地区拥车率排行榜”,同时,他发文表示:中国汽车普及率低于非洲国家尼日利亚,每百户家庭仅17户有车。意大利世界排名第一,每十户中九户有车。
近日,一项新的研究发现,维生素 C 和 E 等抗氧化剂会激活一种机制,刺激癌症肿瘤中新血管的生长,帮助它们生长和扩散。
据媒体援引消息人士报道,苹果公司正在测试使用3D打印技术来生产其智能手表的钢质底盘。消息传出后,3D系统一度大涨超10%,不过截至周三收盘,该股涨幅回落至2%以内。
9月2日,坐拥千万粉丝的网红主播“秀才”账号被封禁,在社交媒体平台上引发热议。平台相关负责人表示,“秀才”账号违反平台相关规定,已封禁。据知情人士透露,秀才近期被举报存在违法行为,这可能是他被封禁的部分原因。据悉,“秀才”年龄39岁,是安徽省亳州市蒙城县人,抖音网红,粉丝数量超1200万。他曾被称为“中老年...
9月3日消息,亚马逊的一些股东,包括持有该公司股票的一家养老基金,日前对亚马逊、其创始人贝索斯和其董事会提起诉讼,指控他们在为 Project Kuiper 卫星星座项目购买发射服务时“违反了信义义务”。
据消息,为推广自家应用,苹果现推出了一个名为“Apps by Apple”的网站,展示了苹果为旗下产品(如 iPhone、iPad、Apple Watch、Mac 和 Apple TV)开发的各种应用程序。
特斯拉本周在美国大幅下调Model S和X售价,引发了该公司一些最坚定支持者的不满。知名特斯拉多头、未来基金(Future Fund)管理合伙人加里·布莱克发帖称,降价是一种“短期麻醉剂”,会让潜在客户等待进一步降价。
据外媒9月2日报道,荷兰半导体设备制造商阿斯麦称,尽管荷兰政府颁布的半导体设备出口管制新规9月正式生效,但该公司已获得在2023年底以前向中国运送受限制芯片制造机器的许可。
近日,根据美国证券交易委员会的文件显示,苹果卫星服务提供商 Globalstar 近期向马斯克旗下的 SpaceX 支付 6400 万美元(约 4.65 亿元人民币)。用于在 2023-2025 年期间,发射卫星,进一步扩展苹果 iPhone 系列的 SOS 卫星服务。
据报道,马斯克旗下社交平台𝕏(推特)日前调整了隐私政策,允许 𝕏 使用用户发布的信息来训练其人工智能(AI)模型。新的隐私政策将于 9 月 29 日生效。新政策规定,𝕏可能会使用所收集到的平台信息和公开可用的信息,来帮助训练 𝕏 的机器学习或人工智能模型。
9月2日,荣耀CEO赵明在采访中谈及华为手机回归时表示,替老同事们高兴,觉得手机行业,由于华为的回归,让竞争充满了更多的可能性和更多的魅力,对行业来说也是件好事。
《自然》30日发表的一篇论文报道了一个名为Swift的人工智能(AI)系统,该系统驾驶无人机的能力可在真实世界中一对一冠军赛里战胜人类对手。
近日,非营利组织纽约真菌学会(NYMS)发出警告,表示亚马逊为代表的电商平台上,充斥着各种AI生成的蘑菇觅食科普书籍,其中存在诸多错误。
社交媒体平台𝕏(原推特)新隐私政策提到:“在您同意的情况下,我们可能出于安全、安保和身份识别目的收集和使用您的生物识别信息。”
2023年德国柏林消费电子展上,各大企业都带来了最新的理念和产品,而高端化、本土化的中国产品正在不断吸引欧洲等国际市场的目光。
罗永浩日前在直播中吐槽苹果即将推出的 iPhone 新品,具体内容为:“以我对我‘子公司’的了解,我认为 iPhone 15 跟 iPhone 14 不会有什么区别的,除了序(列)号变了,这个‘不要脸’的东西,这个‘臭厨子’。