ART运行时与Dalvik虚拟机一样,都使用了Mark-Sweep算法进行垃圾回收,因此它们的垃圾回收流程在总体上是一致的。但是ART运行时对堆的划分更加细致,因而在此基础上实现了更多样的回收策略。不同的策略有不同的回收力度,力度越大的回收策略,每次回收的内存就越多,并且它们都有各自的使用情景。这样就可以使得每次执行GC时,可以最大限度地减少应用程序停顿。本文就详细分析ART运行时的垃圾收集过程。
ART运行时的垃圾收集收集过程如图1所示:
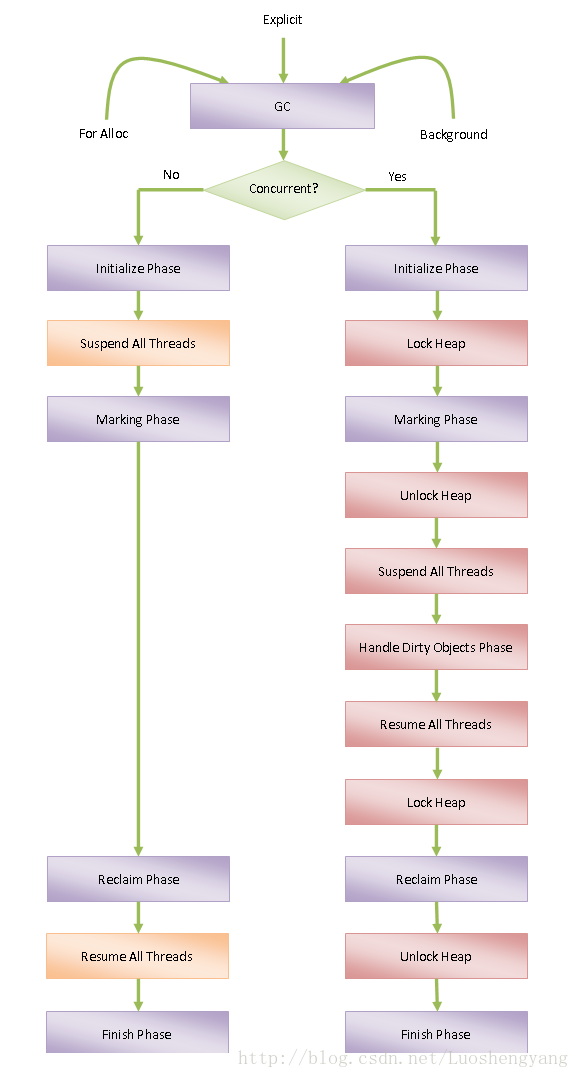
图1 ART运行时的GC执行流程
图1的最上面三个箭头描述触发GC的三种情况,左边的流程图描述非并行GC的执行过程,右边的流程图描述并行GC的执行流程,接下来我们就详细图中涉及到的所有细节。
在前面ART运行时为新创建对象分配内存的过程分析一文中,我们提到了两种可能会触发GC的情况。第一种情况是没有足够内存分配请求的分存时,会调用Heap类的成员函数CollectGarbageInternal触发一个原因为kGcCauseForAlloc的GC。第二种情况下分配出请求的内存之后,堆剩下的内存超过一定的阀值,就会调用Heap类的成员函数RequestConcurrentGC请求执行一个并行GC。
Heap类的成员函数RequestConcurrentGC的实现如下所示:
[cpp] view plaincopy

- void Heap::RequestConcurrentGC(Thread* self) {
- // Make sure that we can do a concurrent GC.
- Runtime* runtime = Runtime::Current();
- DCHECK(concurrentgc);
- if (runtime == NULL || !runtime->IsFinishedStarting() ||
- !runtime->IsConcurrentGcEnabled()) {
- return;
- }
- {
- MutexLock mu(self, *Locks::runtime_shutdownlock);
- if (runtime->IsShuttingDown()) {
- return;
- }
- }
- if (self->IsHandlingStackOverflow()) {
- return;
- }
-
- // We already have a request pending, no reason to start more until we update
- // concurrent_startbytes.
- concurrent_startbytes = std::numeric_limits::max();
-
- JNIEnv* env = self->GetJniEnv();
- DCHECK(WellKnownClasses::java_lang_Daemons != NULL);
- DCHECK(WellKnownClasses::java_lang_Daemons_requestGC != NULL);
- env->CallStaticVoidMethod(WellKnownClasses::java_lang_Daemons,
- WellKnownClasses::java_lang_Daemons_requestGC);
- CHECK(!env->ExceptionCheck());
- }
这个函数定义在文件art/runtime/gc/heap.cc。
只有满足以下四个条件,Heap类的成员函数RequestConcurrentGC才会触发一个并行GC:
1. ART运行时已经启动完毕。
2. ART运行时支持并行GC。ART运行时默认是支持并行GC的,但是可以通过启动选项-Xgc来关闭。
3. ART运行时不是正在关闭。
4. 当前线程没有发生栈溢出。
上述4个条件都满足之后,Heap类的成员函数RequestConcurrentGC就将成员变量concurrent_start_bytes_的值设置为类型size_t的最大值,表示目前正有一个并行GC在等待执行,以阻止触发另外一个并行GC。
最后,Heap类的成员函数RequestConcurrentGC调用Java层的java.lang.Daemons类的静态成员函数requestGC请求执行一次并行GC。Java层的java.lang.Daemons类在加载的时候,会启动五个与堆或者GC相关的守护线程,如下所示:
[java] view plaincopy
- public final class Daemons {
- ......
-
- public static void start() {
- ReferenceQueueDaemon.INSTANCE.start();
- FinalizerDaemon.INSTANCE.start();
- FinalizerWatchdogDaemon.INSTANCE.start();
- HeapTrimmerDaemon.INSTANCE.start();
- GCDaemon.INSTANCE.start();
- }
-
- ......
- }
这个类定义在文件libcore/libart/src/main/java/java/lang/Daemons.java中。
这五个守护线程分别是:
1. ReferenceQueueDaemon:引用队列守护线程。我们知道,在创建引用对象的时候,可以关联一个队列。当被引用对象引用的对象被GC回收的时候,被引用对象就会被加入到其创建时关联的队列去。这个加入队列的操作就是由ReferenceQueueDaemon守护线程来完成的。这样应用程序就可以知道那些被引用对象引用的对象已经被回收了。
2. FinalizerDaemon:析构守护线程。对于重写了成员函数finalize的对象,它们被GC决定回收时,并没有马上被回收,而是被放入到一个队列中,等待FinalizerDaemon守护线程去调用它们的成员函数finalize,然后再被回收。
3. FinalizerWatchdogDaemon:析构监护守护线程。用来监控FinalizerDaemon线程的执行。一旦检测那些重定了成员函数finalize的对象在执行成员函数finalize时超出一定的时候,那么就会退出VM。
4. HeapTrimmerDaemon:堆裁剪守护线程。用来执行裁剪堆的操作,也就是用来将那些空闲的堆内存归还给系统。
5. GCDaemon:并行GC线程。用来执行并行GC。
Java层的java.lang.Daemons类的静态成员函数requestGC被调用时,就会唤醒上述的并行GC线程,然后这个并行GC线程就会通过JNI调用Heap类的成员函数ConcurrentGC,它的实现如下所示:
[cpp] view plaincopy
- void Heap::ConcurrentGC(Thread* self) {
- {
- MutexLock mu(self, *Locks::runtime_shutdownlock);
- if (Runtime::Current()->IsShuttingDown()) {
- return;
- }
- }
-
- // Wait for any GCs currently running to finish.
- if (WaitForConcurrentGcToComplete(self) == collector::kGcTypeNone) {
- CollectGarbageInternal(next_gctype, kGcCauseBackground, false);
- }
- }
这个函数定义在文件art/runtime/gc/heap.cc中。
只要ART运行时当前不是处于正在关闭的状态,那么Heap类的成员函数ConcurrentGC就会检查当前是否正在执行GC。如果是的话,那么就等待它执行完成,然后再调用Heap类的成员函数CollectGarbageInternal触发一个原因为kGcCauseBackground的GC。否则的话,就直接调用Heap类的成员函数CollectGarbageInternal触发一个原因为kGcCauseBackground的GC。
从这里就可以看到,无论是触发GC的原因是kGcCauseForAlloc,还是kGcCauseBackground,最终都是通过调用Heap类的成员函数CollectGarbageInternal来执行GC的。此外,还有第三种情况会触发GC,如下所示:
[cpp] view plaincopy
- void Heap::CollectGarbage(bool clear_soft_references) {
- // Even if we waited for a GC we still need to do another GC since weaks allocated during the
- // last GC will not have necessarily been cleared.
- Thread* self = Thread::Current();
- WaitForConcurrentGcToComplete(self);
- CollectGarbageInternal(collector::kGcTypeFull, kGcCauseExplicit, clear_soft_references);
- }
这个函数定义在文件art/runtime/gc/heap.cc。
当我们调用Java层的java.lang.System的静态成员函数gc时,如果ART运行时支持显式GC,那么就它就会通过JNI调用Heap类的成员函数CollectGarbageInternal来触发一个原因为kGcCauseExplicit的GC。ART运行时默认是支持显式GC的,但是可以通过启动选项-XX:+DisableExplicitGC来关闭。
从上面的分析就可以看出,ART运行时在三种情况下会触发GC,这三种情况通过三个枚举kGcCauseForAlloc、kGcCauseBackground和kGcCauseExplicitk来描述。这三人枚举的定义如下所示:
[cpp] view plaincopy
- // What caused the GC?
- enum GcCause {
- // GC triggered by a failed allocation. Thread doing allocation is blocked waiting for GC before
- // retrying allocation.
- kGcCauseForAlloc,
- // A background GC trying to ensure there is free memory ahead of allocations.
- kGcCauseBackground,
- // An explicit System.gc() call.
- kGcCauseExplicit,
- };
这三个枚举定义在文件art/runtime/gc/heap.h中。
从上面的分析还可以看出,ART运行时的所有GC都是以Heap类的成员函数CollectGarbageInternal为入口,它的实现如下所示:
[cpp] view plaincopy
- collector::GcType Heap::CollectGarbageInternal(collector::GcType gc_type, GcCause gc_cause,
- bool clear_soft_references) {
- Thread* self = Thread::Current();
- ......
-
- // Ensure there is only one GC at a time.
- bool start_collect = false;
- while (!start_collect) {
- {
- MutexLock mu(self, *gc_completelock);
- if (!is_gcrunning) {
- is_gcrunning = true;
- start_collect = true;
- }
- }
- if (!start_collect) {
- // TODO: timinglog this.
- WaitForConcurrentGcToComplete(self);
- ......
- }
- }
-
- ......
-
- if (gc_type == collector::kGcTypeSticky &&
- allocspace->Size() < min_alloc_space_size_for_stickygc) {
- gc_type = collector::kGcTypePartial;
- }
-
- ......
-
- collector::MarkSweep* collector = NULL;
- for (const auto& cur_collector : mark_sweepcollectors) {
- if (cur_collector->IsConcurrent() == concurrentgc && cur_collector->GetGcType() == gc_type) {
- collector = cur_collector;
- break;
- }
- }
- ......
-
- collector->clear_softreferences = clear_soft_references;
- collector->Run();
- ......
-
- {
- MutexLock mu(self, *gc_completelock);
- is_gcrunning = false;
- last_gctype = gc_type;
- // Wake anyone who may have been waiting for the GC to complete.
- gc_completecond->Broadcast(self);
- }
-
- ......
-
- return gc_type;
- }
这个函数定义在文件art/runtime/gc/heap.cc。
参数gc_type和gc_cause分别用来描述要执行的GC的类型和原因,而参数clear_soft_references用来描述是否要回收被软引用对象引用的对象。
Heap类的成员函数CollectGarbageInternal的执行逻辑如下所示:
1. 通过一个while循环不断地检查Heap类的成员变量is_gcrunning,直到它的值等于false为止,这表示当前没有其它线程正在执行GC。当它的值等于true时,就表示在其它线程正在执行GC,这时候就要调用Heap类的成员函数WaitForConcurrentGcToComplete等待其执行完成。注意,在当前GC执行之前,Heap类的成员变量is_gc_running_会被设置为true。
2. 如果当前请求执行的GC的类型为kGcTypeSticky,但是当前Allocation Space的大小小于Heap类的成员变量min_alloc_space_size_for_sticky_gc_指定的阀值,那么就改为执行类型为kGcTypePartial。关于类型为kGcTypeSticky的GC的执行限制,可以参数前面ART运行时为新创建对象分配内存的过程分析一文。
3. 从Heap类的成员变量mark_sweep_collectors_指向的一个垃圾收集器列表找到一个合适的垃圾收集器来执行GC。从前面ART运行时Java堆创建过程分析一文可以知道,ART运行时在内部创建了六个垃圾收集器。这六个垃圾收集器分为两组,一组支持并行GC,另一组不支持。每一组都是由三个类型分别为kGcTypeSticky、kGcTypePartial和kGcTypeFull的垃垃圾收集器组成。这里说的合适的垃圾收集器,是指并行性与Heap类的成员变量concurrent_gc_一致,并且类型也与参数gc_type一致的垃圾收集器。
4. 找到合适的垃圾收集器之后,就将参数clear_soft_references的值保存它的成员变量clear_soft_references_中,以便可以告诉它要不要回收被软引用对象引用的对象,然后再调用它的成员函数Run来执行GC。
5. GC执行完毕,将Heap类的成员变量is_gc_running_设置为false,以表示当前GC已经执行完毕,下一次请求的GC可以执行了。此外,也会将Heap类的成员变量last_gc_type_设置为当前执行的GC的类型。这样下一次执行GC时,就可以执行另外一个不同类型的GC。例如,如果上一次执行的GC的类型为kGcTypeSticky,那么接下来的两次GC的类型就可以设置为kGcTypePartial和kGcTypeFull,这样可以使得每次都能执行有效的GC。
6. 通过Heap类的成员变量gc_complete_cond_唤醒那些正在等待GC执行完成的线程。
在上面的六个步骤中,最重要的就是第四步了。从前面ART运行时垃圾收集机制简要介绍和学习计划一文可以知道,所有的垃圾收集器都是从GarbageCollector类继承下来的,因此上面的第四步实际上执行的是GarbageCollector类的成员函数Run,它的实现如下所示:
[cpp] view plaincopy
- void GarbageCollector::Run() {
- ThreadList* thread_list = Runtime::Current()->GetThreadList();
- uint64_t start_time = NanoTime();
- pausetimes.clear();
- durationns = 0;
-
- InitializePhase();
-
- if (!IsConcurrent()) {
- // Pause is the entire length of the GC.
- uint64_t pause_start = NanoTime();
- ATRACE_BEGIN("Application threads suspended");
- thread_list->SuspendAll();
- MarkingPhase();
- ReclaimPhase();
- thread_list->ResumeAll();
- ATRACE_END();
- uint64_t pause_end = NanoTime();
- pausetimes.push_back(pause_end - pause_start);
- } else {
- Thread* self = Thread::Current();
- {
- ReaderMutexLock mu(self, *Locks::mutatorlock);
- MarkingPhase();
- }
- bool done = false;
- while (!done) {
- uint64_t pause_start = NanoTime();
- ATRACE_BEGIN("Suspending mutator threads");
- thread_list->SuspendAll();
- ATRACE_END();
- ATRACE_BEGIN("All mutator threads suspended");
- done = HandleDirtyObjectsPhase();
- ATRACE_END();
- uint64_t pause_end = NanoTime();
- ATRACE_BEGIN("Resuming mutator threads");
- thread_list->ResumeAll();
- ATRACE_END();
- pausetimes.push_back(pause_end - pause_start);
- }
- {
- ReaderMutexLock mu(self, *Locks::mutatorlock);
- ReclaimPhase();
- }
- }
-
- uint64_t end_time = NanoTime();
- durationns = end_time - start_time;
-
- FinishPhase();
- }
这个函数定义在文件art/runtime/gc/collector/garbage_collector.cc中。
GarbageCollector类的成员函数Run的实现就对应于图1所示的左边和右边的两个流程。
图1所示的左边流程是用来执行非并行GC的,过程如下所示:
1. 调用子类实现的成员函数InitializePhase执行GC初始化阶段。
2. 挂起所有的ART运行时线程。
3. 调用子类实现的成员函数MarkingPhase执行GC标记阶段。
4. 调用子类实现的成员函数ReclaimPhase执行GC回收阶段。
5. 恢复第2步挂起的ART运行时线程。
6. 调用子类实现的成员函数FinishPhase执行GC结束阶段。
图1所示的右边流程是用来执行并行GC的,过程如下所示:
1. 调用子类实现的成员函数InitializePhase执行GC初始化阶段。
2. 获取用于访问Java堆的锁。
3. 调用子类实现的成员函数MarkingPhase执行GC并行标记阶段。
4. 释放用于访问Java堆的锁。
5. 挂起所有的ART运行时线程。
6. 调用子类实现的成员函数HandleDirtyObjectsPhase处理在GC并行标记阶段被修改的对象。。
7. 恢复第4步挂起的ART运行时线程。
8. 重复第5到第7步,直到所有在GC并行阶段被修改的对象都处理完成。
9. 获取用于访问Java堆的锁。
10. 调用子类实现的成员函数ReclaimPhase执行GC回收阶段。
11. 释放用于访问Java堆的锁。
12. 调用子类实现的成员函数FinishPhase执行GC结束阶段。
从上面的分析就可以看出,并行GC和非并行GC的区别在于:
1. 非并行GC的标记阶段和回收阶段是在挂住所有的ART运行时线程的前提下进行的,因此,只需要执行一次标记即可。
2. 并行GC的标记阶段只锁住了Java堆,因此它不能阻止那些不是正在分配对象的ART运行时线程同时运行,而这些同进运行的ART运行时线程可能会引用了一些在之前的标记阶段没有被标记的对象。如果不对这些对象进行重新标记的话,那么就会导致它们被GC回收,造成错误。因此,与非并行GC相比,并行GC多了一个处理脏对象的阶段。所谓的脏对象就是我们前面说的在GC标记阶段同时运行的ART运行时线程访问或者修改过的对象。
3. 并行GC并不是自始至终都是并行的,例如,处理脏对象的阶段就是需要挂起除GC线程以外的其它ART运行时线程,这样才可以保证标记阶段可以结束。
从前面ART运行时垃圾收集机制简要介绍和学习计划一文可以知道,GarbageCollector类有三个直接或者间接的子类MarkSweep、PartialMarkSweep和StickyMarkSweep都可以用来执行垃圾回收,其中,PartialMarkSweep类又是从MarkSweep类直接继承下来的,而StickyMarkSweep类是从PartialMarkSweep类直接继承下来的。MarkSweep类用来回收Zygote Space和Allocation Space的垃圾,PartialMarkSweep类用来回收Allocation Space的垃圾,StickyMarkSweep类用来回收上次GC以来在Allcation Space上分配的最终又没有被引用的垃圾。
接下来,我们就主要分析ART运行时线程的挂起和恢复过程,以及MarkSweep、PartialMarkSweep和StickyMarkSweep这三个类是执行InitializePhase、MarkingPhase、HandleDirtyObjectsPhase、ReclaimPhase和FinishPhase的五个GC阶段的过程。
1. ART运行时线程的挂起
从上面的分析可以知道,ART运行时线程的挂起是通过调用ThreadList类的成员函数SuspendAll实现的,如下所示:
[cpp] view plaincopy
- void ThreadList::SuspendAll() {
- Thread* self = Thread::Current();
- ......
-
- {
- MutexLock mu(self, *Locks::thread_listlock);
- {
- MutexLock mu2(self, *Locks::thread_suspend_countlock);
- // Update global suspend all state for attaching threads.
- ++suspend_allcount;
- // Increment everybody's suspend count (except our own).
- for (const auto& thread : list_) {
- if (thread == self) {
- continue;
- }
- ......
- thread->ModifySuspendCount(self, +1, false);
- }
- }
- }
-
- // Block on the mutator lock until all Runnable threads release their share of access.
-
if HAVE_TIMED_RWLOCK
- // Timeout if we wait more than 30 seconds.
- if (UNLIKELY(!Locks::mutatorlock->ExclusiveLockWithTimeout(self, 30 * 1000, 0))) {
- UnsafeLogFatalForThreadSuspendAllTimeout(self);
- }
-
else
- Locks::mutatorlock->ExclusiveLock(self);
-
endif
-
- ......
- }
这个函数定义在文件art/runtime/thread_list.cc中。
所有的ART运行时线程都保存在ThreadList类的成员变量list_描述的一个列表,遍历这个列表时,需要获取Lock类的成员变量thread_list_lock_描述的一个互斥锁。
ThreadList类有一个成员变量suspend_allcount,用来描述全局的线程挂起计数器。在所有的ART运行时线程挂起期间,如果有新的线程将自己注册为ART运行时线程,那么它也会将自己挂起来,而判断所有的ART运行时线程是不是处于挂起期间,就是通过ThreadList类的成员变量suspend_all_count_的值是否大于0进行的。因此,ThreadList类的成员函数SuspendAll在挂起所有的ART运行时线程之前,会将ThreadList类的成员变量suspend_all_count_的值增加1。
接下来,ThreadList类的成员函数SuspendAll遍历所有的ART运行时线程,并且调用Thread类的成员函数ModifySuspendCount将它内部的线程计算数器增加1,如下所示:
[cpp] view plaincopy
- void Thread::AtomicSetFlag(ThreadFlag flag) {
- android_atomic_or(flag, &state_andflags.as_int);
- }
-
- void Thread::AtomicClearFlag(ThreadFlag flag) {
- android_atomic_and(-1 ^ flag, &state_andflags.as_int);
- }
-
- ......
-
- void Thread::ModifySuspendCount(Thread* self, int delta, bool for_debugger) {
- ......
-
- suspendcount += delta;
- ......
-
- if (suspendcount == 0) {
- AtomicClearFlag(kSuspendRequest);
- } else {
- AtomicSetFlag(kSuspendRequest);
- }
- }
这三个函数定义在文件art/runtime/thread.cc中。
Thread类的成员函数ModifySuspendCount的实现很简单,它主要就是将成员变量suspend_count_的值增加delta,并且判断增加后的值是否等于0。如果等于0,就调用成员函数AtomicClearFlag将另外一个成员变量state_and_flags_的int值的kSuspendRequest位清0,表示线程没有挂起请求。否则的话,就调用成员函数AtomicSetFlag将成员变量state_and_flags_的int值的kSuspendRequest位置1,表示线程有挂起请求。
回到前面ThreadList类的成员函数SuspendAll中,全局ART运行时线程挂起计数器和每一个ART运行时线程内部的线程挂起计数器的操作都是需要在获取Locks类的静态成员变量thread_suspend_count_lock_描述的一个互斥锁的前提下进行的。
最后,ThreadList类的成员函数SuspendAll通过获取Locks类的静态成员变量mutator_lock_描述的一个读写锁的写访问来等待所有的ART运行时线程挂起的。这是如何做到的呢?在前面Android运行时ART执行类方法的过程分析一文中,我们提到,ART运行时提供给由DEX字节码翻译而来的本地机器代码使用的一个函数表中,包含了一个pCheckSuspend函数指针,该函数指针指向了函数CheckSuspendFromCode。于是,每一个ART运行时线程在执行本地机器代码的过程中,就会周期性地通过调用函数CheckSuspendFromCode来检查自己是否需要挂起。这一点与前面Dalvik虚拟机垃圾收集(GC)过程分析一文分析的Dalvik虚拟机线程挂起的过程是类似的。
函数CheckSuspendFromCode的实现如下所示:
[cpp] view plaincopy
- void CheckSuspendFromCode(Thread* thread)
- SHARED_LOCKS_REQUIRED(Locks::mutatorlock) {
- ......
- CheckSuspend(thread);
- }
这个函数定义在文件art/runtime/entrypoints/quick/quick_thread_entrypoints.cc中。
函数CheckSuspendFromCode调用另外一个函数CheckSuspend检查当前线程是否需要挂起,后者的实现如下所示:
[cpp] view plaincopy
- static inline void CheckSuspend(Thread* thread) SHARED_LOCKS_REQUIRED(Locks::mutatorlock) {
- for (;;) {
- if (thread->ReadFlag(kCheckpointRequest)) {
- thread->RunCheckpointFunction();
- thread->AtomicClearFlag(kCheckpointRequest);
- } else if (thread->ReadFlag(kSuspendRequest)) {
- thread->FullSuspendCheck();
- } else {
- break;
- }
- }
- }
这个函数定义在文件art/runtime/entrypoints/entrypoint_utils.h中。
从上面的分析可以知道,如果当前线程的线程挂起计数器不等于0,那么它内部的一个标记位kSuspendRequest被设置为1。这时候函数CheckSuspend就会调用Thread类的成员函数FullSuspendCheck来将自己挂起。此外,函数CheckSuspend还会检查线程内部的另外一个标记位kCheckpointRequest是否被设置为1。如果被设置为1的话,那么就说明线程有一个Check Point需要执行,这时候就会先调用Thread类的成员函数RunCheckpointFunction运行该Check Point,接着再将线程内部的标记位kCheckpointRequest清0。关于线程的Check Point,我们后面再分析。
Thread类的成员函数FullSuspendCheck的实现如下所示:
[cpp] view plaincopy
- void Thread::FullSuspendCheck() {
- ......
- // Make thread appear suspended to other threads, release mutatorlock.
- TransitionFromRunnableToSuspended(kSuspended);
- // Transition back to runnable noting requests to suspend, re-acquire share on mutatorlock.
- TransitionFromSuspendedToRunnable();
- ......
- }
这个函数定义在文件art/runtime/thread.cc中。
Thread类的成员函数FullSuspendCheck首先是调用成员函数TransitionFromRunnableToSuspended将自己从运行状态修改为挂起状态,接着再调用成员函数TransitionFromSuspendedToRunnable将自己从挂起状态修改为运行状态。通过Thread类的这两个神奇的成员函数,就实现了将当前线程挂起的功能。接下来我们就继续分析它们是怎么实现的。
Thread类的成员函数TransitionFromRunnableToSuspended的实现如下所示:
[cpp] view plaincopy
- inline void Thread::TransitionFromRunnableToSuspended(ThreadState new_state) {
- ......
- union StateAndFlags old_state_and_flags;
- union StateAndFlags new_state_and_flags;
- do {
- old_state_and_flags = state_andflags;
- // Copy over flags and try to clear the checkpoint bit if it is set.
- new_state_and_flags.as_struct.flags = old_state_and_flags.as_struct.flags & ~kCheckpointRequest;
- new_state_and_flags.as_struct.state = new_state;
- // CAS the value without a memory barrier, that will occur in the unlock below.
- } while (UNLIKELY(android_atomic_cas(old_state_and_flags.as_int, new_state_and_flags.as_int,
- &state_andflags.as_int) != 0));
- // If we toggled the checkpoint flag we must have cleared it.
- uint16_t flag_change = new_state_and_flags.as_struct.flags ^ old_state_and_flags.as_struct.flags;
- if (UNLIKELY((flag_change & kCheckpointRequest) != 0)) {
- RunCheckpointFunction();
- }
- // Release share on mutatorlock.
- Locks::mutatorlock->SharedUnlock(this);
- }
这个函数定义在文件art/runtime/thread-inl.h中。
线程的状态和标记位均保存在Thread类的成员变量state_and_flags_描述的一个Union结构体中。Thread类的成员函数TransitionFromRunnableToSuspended首先是将线程旧的状态和标志位保存起来,然后再清空它的kCheckpointRequest标志位,以及将它的状态设置为参数new_state描述的状态,即kSuspended状态。
设置好线程新的标记位和状态之后,Thread类的成员函数TransitionFromRunnableToSuspended再检查线程原来的标记位kCheckpointRequest是否等于1。如果等于1的话,那么在释放Locks类的静态成员变量mutator_lock_描述的一个读写锁的读访问之前,先调用Thread类的成员函数RunCheckpointFunction来执行线程的Check Point。
Thread类的成员函数TransitionFromSuspendedToRunnable的实现如下所示:
[cpp] view plaincopy
- inline ThreadState Thread::TransitionFromSuspendedToRunnable() {
- bool done = false;
- union StateAndFlags old_state_and_flags = state_andflags;
- int16_t old_state = old_state_and_flags.as_struct.state;
- ......
- do {
- ......
- old_state_and_flags = state_andflags;
- ......
- if (UNLIKELY((old_state_and_flags.as_struct.flags & kSuspendRequest) != 0)) {
- // Wait while our suspend count is non-zero.
- MutexLock mu(this, *Locks::thread_suspend_countlock);
- old_state_and_flags = state_andflags;
- ......
- while ((old_state_and_flags.as_struct.flags & kSuspendRequest) != 0) {
- // Re-check when Thread::resumecond is notified.
- Thread::resumecond->Wait(this);
- old_state_and_flags = state_andflags;
- ......
- }
- ......
- }
- // Re-acquire shared mutatorlock access.
- Locks::mutatorlock->SharedLock(this);
- // Atomically change from suspended to runnable if no suspend request pending.
- old_state_and_flags = state_andflags;
- ......
- if (LIKELY((old_state_and_flags.as_struct.flags & kSuspendRequest) == 0)) {
- union StateAndFlags new_state_and_flags = old_state_and_flags;
- new_state_and_flags.as_struct.state = kRunnable;
- // CAS the value without a memory barrier, that occurred in the lock above.
- done = android_atomic_cas(old_state_and_flags.as_int, new_state_and_flags.as_int,
- &state_andflags.as_int) == 0;
- }
- if (UNLIKELY(!done)) {
- // Failed to transition to Runnable. Release shared mutatorlock access and try again.
- Locks::mutatorlock->SharedUnlock(this);
- }
- } while (UNLIKELY(!done));
- return static_cast(old_state);
- }
这个函数定义在文件art/runtime/thread-inl.h中。
Thread类的成员函数TransitionFromSuspendedToRunnable的实现很简单,它通过一个do...while循环不断地判断自己是否有一个挂起请求。如果有的话,就在Thread类的静态成员变量resume_cond_描述的一个条件变量上进行等待,直到被其它线程唤醒为止。被唤醒之后,又在获取Locks类的静态成员变量mutator_lock_描述的一个读写锁的读访问的前提下,将自己的状态设置为运行状态,即kRunnable。如果设置成功,就结束执行do...while循环。否则的话,就说明又可能有其它线程请求将自己挂起,因此Thread类的成员函数TransitionFromSuspendedToRunnable又需要释放之前获得的读写锁的读访问,然后再重新执行一遍do...while循环。
Thread类的成员函数TransitionFromRunnableToSuspended和TransitionFromSuspendedToRunnable均是在获得Locks类的静态成员变量mutator_lock_描述的读写锁的读访问的前提下执行的。假设执行GC的线程在调用ThreadList类的成员函数SuspendAll获得Locks类的静态成员变量mutator_lock_描述的读写锁的写访问之前,当前线程还没有获得该读写锁的读访问,那么很明显当它要获得读访问时,就会进入等待状态,因为读写锁的读访问和写访问是互斥的。
另一方面,如果执行GC的线程在调用ThreadList类的成员函数SuspendAll获得Locks类的静态成员变量mutator_lock_描述的读写锁的写访问之前,当前线程已经获得了该读写锁的读访问,那么随后它就会调用Thread类的成员函数TransitionFromRunnableToSuspended释放对该读写锁的读访问,因此GC线程就可以获得该读写锁的写访问。等到当前线程再调用Thread类的成员函数TransitionFromSuspendedToRunnable获得该读写锁的读访问时,就会进入等待状态了。
2. ART运行时线程的恢复
理解了ART运行时线程的挂起过程之后,再理解它们的恢复状态就容易多了,这是通过调用ThreadList类的成员函数ResumeAll实现的,如下所示:
[cpp] view plaincopy
- void ThreadList::ResumeAll() {
- Thread* self = Thread::Current();
- ......
-
- Locks::mutatorlock->ExclusiveUnlock(self);
- {
- MutexLock mu(self, *Locks::thread_listlock);
- MutexLock mu2(self, *Locks::thread_suspend_countlock);
- // Update global suspend all state for attaching threads.
- --suspend_allcount;
- // Decrement the suspend counts for all threads.
- for (const auto& thread : list_) {
- if (thread == self) {
- continue;
- }
- thread->ModifySuspendCount(self, -1, false);
- }
-
- // Broadcast a notification to all suspended threads, some or all of
- // which may choose to wake up. No need to wait for them.
- ......
- Thread::resumecond->Broadcast(self);
- }
- ......
- }
这个函数定义在文件art/runtime/thread_list.cc中。
ThreadList类的成员函数ResumeAll所做的事情刚好与成员函数SuspendAll相反,它首先是释放Locks类的静态成员函数mutator_lock_描述的读写锁的写访问,接着再减少ART运行时线程全局挂起计数器以及每一个ART运行时线程内部的挂起计数器,最再唤醒等待在Thread类的静态成员变量resume_cond_描述的一个条件变量上的其它ART运行时线程。
3. InitializePhase
MarkSweep、PartialMarkSweep和StickyMarkSweep三个类的初始化阶段都是相同的,都是由MarkSweep类的成员函数InitializePhase来实现,如下所示:
[cpp] view plaincopy
- void MarkSweep::InitializePhase() {
- timings_.Reset();
- base::TimingLogger::ScopedSplit split("InitializePhase", &timings_);
- markstack = heap_->markstack.get();
- DCHECK(markstack != nullptr);
- SetImmuneRange(nullptr, nullptr);
- soft_referencelist = nullptr;
- weak_referencelist = nullptr;
- finalizer_referencelist = nullptr;
- phantom_referencelist = nullptr;
- cleared_referencelist = nullptr;
- freedbytes = 0;
- freed_large_objectbytes = 0;
- freedobjects = 0;
- freed_largeobjects = 0;
- classcount = 0;
- arraycount = 0;
- othercount = 0;
- large_objecttest = 0;
- large_objectmark = 0;
- classesmarked = 0;
- overheadtime = 0;
- work_chunkscreated = 0;
- work_chunksdeleted = 0;
- referencecount = 0;
- java_langClass = Class::GetJavaLangClass();
- CHECK(java_langClass != nullptr);
-
- FindDefaultMarkBitmap();
-
- // Do any pre GC verification.
- timings_.NewSplit("PreGcVerification");
- heap_->PreGcVerification(this);
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数InitializePhase主要就是重置一下接下来GC要用到的一些成员变量,其中,比较重要的就是调用另外一个成员函数FindDefaultMarkBitmap获取一个Default Mark Bitmap,它的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::FindDefaultMarkBitmap() {
- base::TimingLogger::ScopedSplit split("FindDefaultMarkBitmap", &timings_);
- for (const auto& space : GetHeap()->GetContinuousSpaces()) {
- if (space->GetGcRetentionPolicy() == space::kGcRetentionPolicyAlwaysCollect) {
- current_markbitmap = space->GetMarkBitmap();
- CHECK(current_markbitmap != NULL);
- return;
- }
- }
- ......
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
从这里的就可以看出,Default Mark Bitmap就是回收策略为kGcRetentionPolicyAlwaysCollect的Space对应的Mark Bitmap。从前面ART运行时Java堆创建过程分析一文可以知道,这个Space就是Allocation Space(如果Allocation Space还没有从Zygote Space划分出来,那就是Zygote Space)。
获得的Default Mark Bitmap保存在MarkSweep类的成员变量current_mark_bitmap_中。
4. MarkingPhase
MarkSweep、PartialMarkSweep和StickyMarkSweep三个类的标记阶段都是以MarkSweep类的成员函数MarkingPhase为入口,它的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::MarkingPhase() {
- base::TimingLogger::ScopedSplit split("MarkingPhase", &timings_);
- Thread* self = Thread::Current();
-
- BindBitmaps();
- FindDefaultMarkBitmap();
-
- // Process dirty cards and add dirty cards to mod union tables.
- heap->ProcessCards(timings);
-
- // Need to do this before the checkpoint since we don't want any threads to add references to
- // the live stack during the recursive mark.
- timings_.NewSplit("SwapStacks");
- heap_->SwapStacks();
-
- WriterMutexLock mu(self, *Locks::heap_bitmaplock);
- if (Locks::mutatorlock->IsExclusiveHeld(self)) {
- // If we exclusively hold the mutator lock, all threads must be suspended.
- MarkRoots();
- } else {
- MarkThreadRoots(self);
- // At this point the live stack should no longer have any mutators which push into it.
- MarkNonThreadRoots();
- }
- live_stack_freezesize = heap_->GetLiveStack()->Size();
- MarkConcurrentRoots();
-
- heap->UpdateAndMarkModUnion(this, timings, GetGcType());
- MarkReachableObjects();
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数MarkingPhase标记对象的过程如下所示:
A. 调用成员函数BindBitmap设置回收范围。
B. 调用成员函数FindDefaultMarkBitmap找到回收策略为kGcRetentionPolicyAlwaysCollect的Space对应的Mark Bitmap,并且保存在成员变量current_mark_bitmap_中。这个函数我们在前面已经分析过了。
C. 调用Heap类的成员函数ProcessCards处理Card Table中的Dirty Card,以及这些Dirty Card添加到对应的Mod Union Table中去。
D. 调用Heap类的成员函数SwapStacks交换ART运行时的Allocation Stack和Live Stack。
E. 对于非并行GC,当前线程在挂起其它ART运行时线程的过程中,已经获得Locks类的静态成员变量mutator_lock_描述的读写锁的写访问,因此这时候就调用成员函数MarkRoots来标记那些不可以在没有获得Locks类的静态成员变量mutator_lock_描述的读写锁的情况下访问的根集对象。注意,MarkSweep类的成员函数MarkRoots只通过当前线程来标记根集对象。
F. 对于并行GC,由于标记阶段并没有挂起其它的ART运行时线程,因此这时候就调用成员函数MarkThreadRoots来并发标记那些不可以在没有获得Locks类的静态成员变量mutator_lock_描述的读写锁的情况下访问的位于线程调用栈中的根集对象,接着再在当前线程中调用成员函数MarkNonThreadRoots标记那些不可以在没有获得Locks类的静态成员变量mutator_lock_描述的读写锁的情况下访问的其它根集对象。
G. 获得Live Stack的大小,保存成员变量live_stack_freeze_size_中。注意,这时候Live Stack的大小即为交换Allocation Stack和Live Stack之前Allocation Stack的大小,即从上次GC以来新分配的对象的个数。
H. 调用成员函数MarkConcurrentRoots标记那些可以在没有获得Locks类的静态成员变量mutator_lock_描述的读写锁的情况下访问的根集对象。
I. 调用Heap类的成员函数UpdateAndMarkModUnion处理Mod Union Table中的Dirty Card。
J. 调用成员函数MarkReachableObjects递归标记那些可以从根集对象到达的其它对象。
上述就是GC的标记阶段,它是一个很复杂的过程,涉及到的关键函数有MarkSweep类的成员函数BindBitmap、MarkRoots、MarkThreadRoots、MarkNonThreadRoots、MarkConcurrentRoots和MarkReachableObjects,以及Heap类的成员函数ProcessCards、SwapStacks和UpdateAndMarkModUnion。接下来我们就详细分析这些函数的实现,以及这些函数涉及到的概念。
在前面ART运行时垃圾收集机制简要介绍和学习计划一文中,我们提到,Mark Sweep、Partial Mark Sweep和Sticky Mark Sweep的回收范围是不同的,它们分别通过实现的自己的成员函数BindBitmap来限定回收范围,因此,接下来我们就分别分析MarkSweep、PartialMarkSweep和StickyMarkSweep三个类的成员函数BindBitmap的实现。
MarkSweep类的成员函数BindBitmap的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::BindBitmaps() {
- timings_.StartSplit("BindBitmaps");
- WriterMutexLock mu(Thread::Current(), *Locks::heap_bitmaplock);
- // Mark all of the spaces we never collect as immune.
- for (const auto& space : GetHeap()->GetContinuousSpaces()) {
- if (space->GetGcRetentionPolicy() == space::kGcRetentionPolicyNeverCollect) {
- ImmuneSpace(space);
- }
- }
- timings_.EndSplit();
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数BindBitmap调用另外一个成员函数ImmuneSpace将回收策略为kGcRetentionPolicyNeverCollect的Space的Live Bitmap和Mark Bitmap进行交换,这样做的效果就相当于不对该Space进行GC。从前面ART运行时Java堆创建过程分析一文可以知道,回收策略为kGcRetentionPolicyNeverCollect的Space就是Image Space,因此,MarkSweep类就只对Zygote Space和Allocation Space进行GC。
MarkSweep类的成员函数ImmuneSpace的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::ImmuneSpace(space::ContinuousSpace* space) {
- // Bind live to mark bitmap if necessary.
- if (space->GetLiveBitmap() != space->GetMarkBitmap()) {
- BindLiveToMarkBitmap(space);
- }
-
- // Add the space to the immune region.
- if (immunebegin == NULL) {
- DCHECK(immuneend == NULL);
- SetImmuneRange(reinterpret_cast<Object*>(space->Begin()),
- reinterpret_cast<Object*>(space->End()));
- } else {
- const space::ContinuousSpace* prev_space = nullptr;
- // Find out if the previous space is immune.
- for (space::ContinuousSpace* cur_space : GetHeap()->GetContinuousSpaces()) {
- if (cur_space == space) {
- break;
- }
- prev_space = cur_space;
- }
- // If previous space was immune, then extend the immune region. Relies on continuous spaces
- // being sorted by Heap::AddContinuousSpace.
- if (prev_space != NULL &&
- immunebegin <= reinterpret_cast<Object*>(prev_space->Begin()) &&
- immuneend >= reinterpret_cast<Object*>(prev_space->End())) {
- immunebegin = std::min(reinterpret_cast<Object*>(space->Begin()), immunebegin);
- immuneend = std::max(reinterpret_cast<Object*>(space->End()), immuneend);
- }
- }
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数ImmuneSpace首先是判断参数space描述的Space的Live Bitmap和Mark Bitmap是否是同一个Bitmap。如果是的话,那么就不需要调用成员函数BindLiveToMarkBitmap对它们进行交换了。一般来说,一个Space的Live Bitmap和Mark Bitmap指向的是不同的Bitmap的,但是Image Space比较特殊,它们指向的是同一个Bitmap。这一点在前面ART运行时Java堆创建过程分析一文中有提到。
如果之前有Space也被设置为不进行回收,那么除了调用成员函数BindLiveToMarkBitmap交换参数space描述的Space的Live Bitmap和Mark Bitmap之外,MarkSweep类的成员函数ImmuneSpace还会参数space描述的Space占用的内存区域与之前也被设置为不进行回收的Space占用的内存区域进行合并,最后将得到的不会被回收的内存总区域的开始位置和结束位置记录在MarkSweep类的成员变量immunebegin 和immune_end_中。
另一方面,如果之前没有Space也被设置过不进行回收,那么MarkSweep类的成员函数ImmuneSpace就会将参数space描述的Space占用的内存区域的开始位置和结束位置记录在MarkSweep类的成员变量immunebegin 和immune_end_中,以便 后面可以调用MarkSweep类的成员函数IsImmune判断一个对象是否位于非回收Space中。
MarkSweep类的成员函数IsImmune的实现如下所示:
[cpp] view plaincopy
- class MarkSweep : public GarbageCollector {
- public:
- ......
-
- protected:
- ......
-
- // Returns true if an object is inside of the immune region (assumed to be marked).
- bool IsImmune(const mirror::Object* obj) const {
- return obj >= immunebegin && obj < immuneend;
- }
-
- ......
- };
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数IsImmune只需要将参数obj描述的对象地址与MarkSweep类的成员变量immune_begin_和immune_end_进行比较,就可以知道该对象是否位于非回收Space中了。
PartialMarkSweep类重写了父类MarkSweep的成员函数BindBitmap,它的实现如下所示:
[cpp] view plaincopy
- void PartialMarkSweep::BindBitmaps() {
- MarkSweep::BindBitmaps();
-
- WriterMutexLock mu(Thread::Current(), *Locks::heap_bitmaplock);
- // For partial GCs we need to bind the bitmap of the zygote space so that all objects in the
- // zygote space are viewed as marked.
- for (const auto& space : GetHeap()->GetContinuousSpaces()) {
- if (space->GetGcRetentionPolicy() == space::kGcRetentionPolicyFullCollect) {
- CHECK(space->IsZygoteSpace());
- ImmuneSpace(space);
- }
- }
- }
这个函数定义在文件art/runtime/gc/collector/partial_mark_sweep.cc中。
PartialMarkSweep类的成员函数BindBitmap除了调用父类MarkSweep类的成员函数BindBitmap将Image Space标记为不回收之外,还会将回收策略为kGcRetentionPolicyFullCollect的Space标记为不回收。从前面ART运行时Java堆创建过程分析一文可以知道,回收策略为kGcRetentionPolicyFullCollect的Space就是Zygote Space,因此,MarkSweep类就只对Allocation Space进行GC。
StickyMarkSweep类重写了父类PartialMarkSweep的成员函数BindBitmap,它的实现如下所示:
[cpp] view plaincopy
- void StickyMarkSweep::BindBitmaps() {
- PartialMarkSweep::BindBitmaps();
-
- WriterMutexLock mu(Thread::Current(), *Locks::heap_bitmaplock);
- // For sticky GC, we want to bind the bitmaps of all spaces as the allocation stack lets us
- // know what was allocated since the last GC. A side-effect of binding the allocation space mark
- // and live bitmap is that marking the objects will place them in the live bitmap.
- for (const auto& space : GetHeap()->GetContinuousSpaces()) {
- if (space->GetGcRetentionPolicy() == space::kGcRetentionPolicyAlwaysCollect) {
- BindLiveToMarkBitmap(space);
- }
- }
-
- GetHeap()->GetLargeObjectsSpace()->CopyLiveToMarked();
- }
这个函数定义在文件art/runtime/gc/collector/sticky_mark_sweep.cc中。
StickyMarkSweep类的成员函数BindBitmap除了调用父类PartialMarkSweep类的成员函数BindBitmap将Image Space和Zygote Space标记为不回收之外,还会将回收策略为kGcRetentionPolicyAlwaysCollect的Continuous Space的Live Bitmap和Mark Bitmap进行交换,执行同样操作的还有Large Object Space。从前面ART运行时Java堆创建过程分析一文可以知道,回收策略为kGcRetentionPolicyAlwaysCollect的Space就是Allocation Space,因此,StickyMarkSweep类就只对Allocation Stack进行GC。
这里有一点需要注意的是,在交换Live Bitmap和Mark Bitmap之前,Allocation Space和Large Object Space的Live Bitmap都是没有标记那些上次GC以来分配的对象的,而是记录在Allocation Stack中,因此,虽然上次GC以来分配的对象都是位于Allocation Space或者Large Object Space上的,但是这里交换它们的Live Bitmap和Mark Bitmap并不意味着它们不会被回收。
Heap类的成员函数ProcessCards的实现如下所示:
[cpp] view plaincopy
- void Heap::ProcessCards(base::TimingLogger& timings) {
- // Clear cards and keep track of cards cleared in the mod-union table.
- for (const auto& space : continuousspaces) {
- if (space->IsImageSpace()) {
- base::TimingLogger::ScopedSplit split("ImageModUnionClearCards", &timings);
- image_mod_uniontable->ClearCards(space);
- } else if (space->IsZygoteSpace()) {
- base::TimingLogger::ScopedSplit split("ZygoteModUnionClearCards", &timings);
- zygote_mod_uniontable->ClearCards(space);
- } else {
- base::TimingLogger::ScopedSplit split("AllocSpaceClearCards", &timings);
- // No mod union table for the AllocSpace. Age the cards so that the GC knows that these cards
- // were dirty before the GC started.
- cardtable->ModifyCardsAtomic(space->Begin(), space->End(), AgeCardVisitor(), VoidFunctor());
- }
- }
- }
这个函数定义在文件art/runtime/gc/heap.cc中。
Heap类的成员函数ProcessCards用来处理Card Table里面的Dirty Card,它是在Marking阶段被调用的。回忆前面Dalvik虚拟机垃圾收集(GC)过程分析一文,在Dalvik虚拟机的垃圾收集过程中,Dirty Card是在Handle Dirty Object阶段才处理的,那为什么ART运行时会放在Marking阶段就进行处理呢?实际上,ART运行时在Handle Dirty阶段也会对Dirty Card进行处理。也就是说,在ART运行时的垃圾收集过程中,Dirty Card一共被处理两次,一次在Marking阶段,另一次在Handle Dirty Object阶段。这样做有两个原因。
第一个原因是在ART运行时中,Card Table在并行和非并行GC中都会用到,因此就不能只在Handle Dirty Object阶段才处理。ART运行时中的Card Table在运行期间一直都是用来记录那些修改了引用类型的成员变量的对象的,即这些对象对应的Card都会设置为DIRTY。这些Dirty Card在每次GC时都会进行老化处理。老化处理是通过一个叫AgeCardVisitor的类进行的。每一个Card只有三个可能的值,分别是DIRTY、(DIRTY - 1)和0。当一个对象的引用类型的成员变量被修改之后,它对应的Card的值就会被设置为DIRTY。在接下来的一次GC中,值为DIRTY的Card就会老化为(DIRTY - 1)。在又接下来的GC中,值为(DIRTY-1)的Card就会老化为0。对于值等于DIRTY和(DIRTY - 1)的Card对应的对象,它们在Marking阶段都会被标记。这些对象被标记就意味着它们不会被回收,即使它们不在根集中,并且也不被根集对象引用。尽管这样会造成一些垃圾对象没有及时回收,不过这不会引起程序错误,并且这些对象在再接下来的一次GC中,如果仍然不在根集中,或者不被根集对象引用,那么它们就一定会被回收,因为它们对应的Card已经老化为0了。
第二个原因是与并行GC相关的。我们知道,Handle Dirty Object阶段是在挂起ART运行时线程的前提下进行的,因此,如果把所有的Dirty Card都放在Handle Dirty Object阶段处理,那么就会可能会造成应用程序停顿时间过长。于是,ART运行时就在并行Marking阶段也帮忙着处理Dirty Card,通过这种方式尽量减少在Handle Dirty Object阶段需要处理的Dirty Card,以达到减少应用程序因为GC造成的停顿时间。不过这样就会有一个问题,在Handle Dirty Object阶段,如何知道哪些Dirty Card是在并行Marking阶段已经被处理过的?这就要借助Mod Union Table了。在Marking阶段,当一个Dirty Card被处理过后,它的值就会由DIRTY变成(DIRTY - 1),并且被它引用的对象都会被记录在Mod Union Table中。这样我们就可以在Marking阶段和Handle Dirty Object阶段做到共用同一个Card Table,而且又能够区分不同的阶段出现的Dirty Card。
有了上面的背景知识之后,我们就可以继续分析在Marking阶段与Card Table和Mod Union Table处理相关的逻辑了,即Heap类的成员函数ProcessCards和UpdateAndMarkModUnion的实现。
从前面ART运行时Java堆创建过程分析一文可以知道,Heap类的成员变量image_mod_union_table_指向的是一个ModUnionTableToZygoteAllocspace对象,用来记录在Image Space上分配的对象对在Zygote Space和Allocation Space上分配的对象的引用,另外一个成员变量zygote_mod_union_table_则指向一个ModUnionTableCardCache,用来记录在Zygote Space上分配的对象对在Allocation Space上分配的对象的引用。因此,对于与Image Space和Zygote Space对应的Dirty Card的处理,是分别通过调用ModUnionTableToZygoteAllocspace类和ModUnionTableCardCache类的成员函数ClearCards来进行的。对于Allocation Space,它没有对应的Mod Union Table,因此,与它对应的Dirty Card的处理,就直接在Card Table进行处理,即调用CardTable类的成员函数ModifyCardsAtomic来进行。
我们首先分析与Image Space对应的Dirty Card在标记阶段的处理过程之一,即ModUnionTableToZygoteAllocspace类的成员函数ClearCards的实现,它是从父类ModUnionTableReferenceCache继承下来的,用来将Dirty Card的值从DIRTY减为(DIRTY - 1),如下所示:
[cpp] view plaincopy
- void ModUnionTableReferenceCache::ClearCards(space::ContinuousSpace* space) {
- CardTable* card_table = GetHeap()->GetCardTable();
- ModUnionClearCardSetVisitor visitor(&clearedcards);
- // Clear dirty cards in the this space and update the corresponding mod-union bits.
- card_table->ModifyCardsAtomic(space->Begin(), space->End(), AgeCardVisitor(), visitor);
- }
这个函数定义在文件art/runtime/gc/accounting/mod_union_table.cc中。
参数space指向的是Image Space,ModUnionTableReferenceCache类的成员函数首先找到用来描述ART运行时堆的Card Table,然后再调用它的成员函数ModifyCardsAtomic修改与Image Space对应的那部分Dirty Card的值,具体的修改操作是由第三个参数指定的AgeCardVisitor执行的,第四个参数是一个ModUnionClearCardSetVisitor对象,用来收集缓存那些被修改了的Dirty Card。
CardTable类的成员函数ModifyCardsAtomic的实现如下所示:
[cpp] view plaincopy
- /*
-
- Visitor is expected to take in a card and return the new value. When a value is modified, the
-
- modify visitor is called.
-
- visitor: The visitor which modifies the cards. Returns the new value for a card given an old
-
-
- modified: Whenever the visitor modifies a card, this visitor is called on the card. Enables
-
- us to know which cards got cleared.
- */
- template <typename Visitor, typename ModifiedVisitor>
- inline void CardTable::ModifyCardsAtomic(byte scan_begin, byte scan_end, const Visitor& visitor,
- const ModifiedVisitor& modified) {
- byte* card_cur = CardFromAddr(scan_begin);
- byte* card_end = CardFromAddr(scan_end);
- CheckCardValid(card_cur);
- CheckCardValid(card_end);
-
- // Handle any unaligned cards at the start.
- while (!IsAligned<sizeof(word)>(card_cur) && card_cur < card_end) {
- byte expected, new_value;
- do {
- expected = *card_cur;
- new_value = visitor(expected);
- } while (expected != new_value && UNLIKELY(!byte_cas(expected, new_value, card_cur)));
- if (expected != new_value) {
- modified(card_cur, expected, new_value);
- }
- ++card_cur;
- }
-
- // Handle unaligned cards at the end.
- while (!IsAligned<sizeof(word)>(card_end) && card_end > card_cur) {
- --card_end;
- byte expected, new_value;
- do {
- expected = *card_end;
- new_value = visitor(expected);
- } while (expected != new_value && UNLIKELY(!byte_cas(expected, new_value, card_end)));
- if (expected != new_value) {
- modified(card_cur, expected, new_value);
- }
- }
-
- // Now we have the words, we can process words in parallel.
- uintptr_t word_cur = reinterpret_cast<uintptr_t>(card_cur);
- uintptr_t word_end = reinterpret_cast<uintptr_t>(card_end);
- uintptr_t expected_word;
- uintptr_t new_word;
-
- // TODO: Parallelize.
- while (word_cur < word_end) {
- while ((expected_word = *word_cur) != 0) {
- new_word =
- (visitor((expected_word >> 0) & 0xFF) << 0) |
- (visitor((expected_word >> 8) & 0xFF) << 8) |
- (visitor((expected_word >> 16) & 0xFF) << 16) |
- (visitor((expected_word >> 24) & 0xFF) << 24);
- if (new_word == expected_word) {
- // No need to do a cas.
- break;
- }
- if (LIKELY(android_atomic_cas(expected_word, new_word,
- reinterpret_cast<int32_t*>(word_cur)) == 0)) {
- for (size_t i = 0; i < sizeof(uintptr_t); ++i) {
- const byte expected_byte = (expected_word >> (8 * i)) & 0xFF;
- const byte new_byte = (new_word >> (8 * i)) & 0xFF;
- if (expected_byte != new_byte) {
- modified(reinterpret_cast<byte*>(word_cur) + i, expected_byte, new_byte);
- }
- }
- break;
- }
- }
- ++word_cur;
- }
- }
这个函数定义在文件art/runtime/gc/accounting/card_table-inl.h中。
CardTable类的成员函数ModifyCardsAtomic看起来代码不少,但其实它的逻辑是很简单的。对于参数scan_begin和scan_end描述的Card Table范围内的每一个Card(占一个字节),都通过参数visitor描述的一个AgeCardVisitor进行修改。如果修改后的值与原来的值不相等,则将对应的Card交给参数modified描述的一个ModUnionClearCardSetVisitor进行处理。
不过,CardTable类的成员函数ModifyCardsAtomic不是简单的遍历参数scan_begin和scan_end描述的Card Table范围内的每一个Card,它会对去掉指定的Card Table范围的头部和尾部不是4字节对齐的部分,得到中间开始地址是以4字节为边界、并且长度也是4的倍数的部分。对于不是4字节对齐的头部和尾部,在当前线程逐个Card的遍历,而对于中间4字节对齐的部分,则是充分利用编译器和CPU指令的并发执行特性,以4个字节,即4个Card为单位进行遍历。通过这种方式,就可以大大地提高对Card Table的处理过程。
接下来,我们就继续分析AgeCardVisitor和ModUnionClearCardSetVisitor对传递给它们的每一个Card的处理,它们都是通过操作符重载成员函数()来进行处理的。
AgeCardVisitor类的操作符号重载成员函数()的实现如下所示:
[cpp] view plaincopy
- class AgeCardVisitor {
- public:
- byte operator()(byte card) const {
- if (card == accounting::CardTable::kCardDirty) {
- return card - 1;
- } else {
- return 0;
- }
- }
- };
这个函数定义在文件art/runtime/gc/heap.h中。
AgeCardVisitor类的操作符号成员函数()主要就是将原来值等于kCardDirty的Card设置为(kCardDirty - 1),而其它值都会被设置为0。
ModUnionClearCardSetVisitor类的操作符重载成员函数()的实现如下所示:
[cpp] view plaincopy
- class ModUnionClearCardSetVisitor {
- public:
- explicit ModUnionClearCardSetVisitor(ModUnionTable::CardSet* const cleared_cards)
- : clearedcards(cleared_cards) {
- }
-
- inline void operator()(byte* card, byte expected_value, byte new_value) const {
- if (expected_value == CardTable::kCardDirty) {
- clearedcards->insert(card);
- }
- }
-
- private:
- ModUnionTable::CardSet* const clearedcards;
- };
这个函数定义在文件art/runtime/gc/accounting/mod_union_table.cc中。
ModUnionClearCardSetVisitor类的操作符重载成员函数()主要就是将原来值等于kCardDirty的Card保存在成员变量cleared_cards_指向的一个CardSet中。注意,这个CardSet实际上就是前面提到的ModUnionTableReferenceCache类的成员变量cleared_cards_指向的CardSet。
这样,等到ModUnionTableReferenceCache类的成员函数ClearCards执行完毕,所有与Image Space对应的Dirty Card的值都被减少了1,并且保存在成员变量cleared_cards_指向的CardSet了。
ModUnionTableCardCache类的成员函数ClearCards用来处理与Zygote Space对应的Card Table,它的实现如下所示:
[cpp] view plaincopy
- void ModUnionTableCardCache::ClearCards(space::ContinuousSpace* space) {
- CardTable* card_table = GetHeap()->GetCardTable();
- ModUnionClearCardSetVisitor visitor(&clearedcards);
- // Clear dirty cards in the this space and update the corresponding mod-union bits.
- card_table->ModifyCardsAtomic(space->Begin(), space->End(), AgeCardVisitor(), visitor);
- }
这个函数定义在文件art/runtime/gc/accounting/mod_union_table.cc中。
从这里就可以看出,ModUnionTableCardCache类的成员函数ClearCards的实现与我们前面分析的ModUnionTableReferenceCache类的成员函数ClearCards是一样的,只不过它处理的是与Zygote Space对应的Card Table。
这样,等到ModUnionTableCardCache类的成员函数ClearCards执行完毕,所有与Zygote Space对应的Dirty Card的值都被减少了1,并且保存在成员变量cleared_cards_指向的CardSet了。
回到前面的Heap类的成员函数ProcessCards中,与Allocation Space对应的Card Table直接通过前面分析过的CardTable类的成员函数ModifyCardsAtomic直接处理。并且在调用CardTable类的成员函数ModifyCardsAtomic的时候,指定的第三个参数同样是AgeCardVisitor,而第四个参数是一个什么也不做的VoidFunctor。这意味着与与Allocation Space对应的Dirty Card除了值减少1之外,基它什么也没有发生。
上面对Card Table的处理都是在Marking阶段开始的时候进行的,在Marking阶段结束之前,还会再次调用Heap类的成员函数UpdateAndMarkModUnion对Card Table中的Dirty Card进行处理。
Heap类的成员函数UpdateAndMarkModUnion的实现如下所示:
[cpp] view plaincopy
- void Heap::UpdateAndMarkModUnion(collector::MarkSweep* mark_sweep, base::TimingLogger& timings,
- collector::GcType gc_type) {
- if (gc_type == collector::kGcTypeSticky) {
- // Don't need to do anything for mod union table in this case since we are only scanning dirty
- // cards.
- return;
- }
-
- base::TimingLogger::ScopedSplit split("UpdateModUnionTable", &timings);
- // Update zygote mod union table.
- if (gc_type == collector::kGcTypePartial) {
- base::TimingLogger::ScopedSplit split("UpdateZygoteModUnionTable", &timings);
- zygote_mod_uniontable->Update();
-
- timings.NewSplit("ZygoteMarkReferences");
- zygote_mod_uniontable->MarkReferences(mark_sweep);
- }
-
- // Processes the cards we cleared earlier and adds their objects into the mod-union table.
- timings.NewSplit("UpdateModUnionTable");
- image_mod_uniontable->Update();
-
- // Scans all objects in the mod-union table.
- timings.NewSplit("MarkImageToAllocSpaceReferences");
- image_mod_uniontable->MarkReferences(mark_sweep);
- }
这个函数定义在文件art/runtime/gc/heap.cc中。
对于Sticky Mark Sweep,Card Table里面的Dirty Card不是在Heap类的成员函数UpdateAndMarkModUnion处理的,而是在Marking阶段的最后Marking Reachable Objects过程中处理的。
对于Partial Mark Sweep,需要处理的Card Table包括Image Space和Zygote Space对应的Card Table,而对于Full Mark Sweep,需要处理的Card Table只有Image Space对应的Card Table。
由于Image Space和Zygote Space对应的Card Table中的Dirty Card在前面都已经处理过了,并且它们都已经分别缓存在ModUnionTableToZygoteAllocspace类和ModUnionTableCardCache类的成员变量cleared_cards_指向的CardSet中了,因此,这时候主要对这两个CardSet中的Dirty Card进行处理就行了。
我们先回顾一下,Dirty Card记录的是在不需要进行回收的Space上分配的并且在GC过程中类型为引用的成员变量被修改过的对象,这些被修改的引用类型的成员变量有可能指向了一个在需要进行回收的Space上分配的对象,而这些对象可能不在根集中,因此就需要将将它们当作根集对象一样进行标记。为了方便下面的描述,我们将这些需要像根集对象一样进行标记的对象称为被Dirty Card引用的对象。
对于被与Image Space对应的Dirty Card引用的对象,是通过调用ModUnionTableToZygoteAllocspace类的成员函数Update和MarkReferences进行的,它们均是从父类ModUnionTableReferenceCache继承下来的,因此接下来我们就分析ModUnionTableReferenceCache类的成员函数Update和MarkReferences的实现。
ModUnionTableReferenceCache类的成员函数Update的实现如下所示:
[cpp] view plaincopy
- void ModUnionTableReferenceCache::Update() {
- Heap* heap = GetHeap();
- CardTable* card_table = heap->GetCardTable();
-
- std::vector<const Object*> cards_references;
- ModUnionReferenceVisitor visitor(this, &cards_references);
-
- for (const auto& card : clearedcards) {
- // Clear and re-compute alloc space references associated with this card.
- cards_references.clear();
- uintptr_t start = reinterpret_cast(card_table->AddrFromCard(card));
- uintptr_t end = start + CardTable::kCardSize;
- auto space = heap->FindContinuousSpaceFromObject(reinterpret_cast<Object>(start), false);
- DCHECK(space != nullptr);
- SpaceBitmap* live_bitmap = space->GetLiveBitmap();
- live_bitmap->VisitMarkedRange(start, end, visitor);
-
- // Update the corresponding references for the card.
- auto found = references_.find(card);
- if (found == references_.end()) {
- if (cards_references.empty()) {
- // No reason to add empty array.
- continue;
- }
- references_.Put(card, cards_references);
- } else {
- found->second = cards_references;
- }
- }
- clearedcards.clear();
- }
这个函数定义在文件art/runtime/gc/accounting/mod_union_table.cc中。
ModUnionTableReferenceCache类的成员函数Update主要就是对前面保存在成员变量cleared_cards_描述的一个CardSet中的每一个Dirty Card进行遍历,并且找到这些Dirty Card对应的对象,然后再通过ModUnionReferenceVisitor的操作符重载成员函数()对这些对象的引用类型的成员变量引用的对象进行收集,并且保存在另外一个成员变量references_描述的一个SafeMap中。
ModUnionReferenceVisitor类的操作符重载成员函数()的实现如下所示:
[cpp] view plaincopy
- class ModUnionReferenceVisitor {
- public:
- explicit ModUnionReferenceVisitor(ModUnionTableReferenceCache* const mod_union_table,
- std::vector<const Object> references)
- : mod_uniontable(mod_union_table),
- references_(references) {
- }
-
- void operator()(const Object* obj) const
- SHARED_LOCKS_REQUIRED(Locks::heap_bitmaplock, Locks::mutatorlock) {
- DCHECK(obj != NULL);
- // We don't have an early exit since we use the visitor pattern, an early
- // exit should significantly speed this up.
- AddToReferenceArrayVisitor visitor(mod_uniontable, references_);
- collector::MarkSweep::VisitObjectReferences(obj, visitor);
- }
- private:
- ModUnionTableReferenceCache* const mod_uniontable;
- std::vector<const Object> const references_;
- };
这个函数定义在文件art/runtime/gc/accounting/mod_union_table.cc中。
参数obj描述的是便是与Dirty Card对应的对象,现在需要通过MarkSweep类的成员函数VisitObjectReferences遍历它那些引用类型的成员变量,这些成员变量将被AddToReferenceArrayVisitor类的操作符重载成员函数()进行处理。
AddToReferenceArrayVisitor类的操作符重载成员函数()的实现如下所示:
[cpp] view plaincopy
- class AddToReferenceArrayVisitor {
- public:
- explicit AddToReferenceArrayVisitor(ModUnionTableReferenceCache* mod_union_table,
- std::vector<const Object> references)
- : mod_uniontable(mod_union_table),
- references_(references) {
- }
-
- // Extra parameters are required since we use this same visitor signature for checking objects.
- void operator()(const Object obj, const Object ref, const MemberOffset& / offset /,
- bool / is_static /) const {
- // Only add the reference if it is non null and fits our criteria.
- if (ref != NULL && mod_uniontable->AddReference(obj, ref)) {
- references_->push_back(ref);
- }
- }
-
- private:
- ModUnionTableReferenceCache* const mod_uniontable;
- std::vector<const Object> const references_;
- };
这个函数定义在文件art/runtime/gc/accounting/mod_union_table.cc中。
参数obj是一个与Dirty Card对应的对象,而参数ref是对象obj的一个引用类型的成员变量指向的对象。AddToReferenceArrayVisitor类的操作符重载成员函数()通过调用成员变量mod_union_table_指向的是一个ModUnionTableToZygoteAllocspace对象的成员函数AddReference来判断是否需要将参数ref指向的对象添加到成员变量references_指向的一个vector中。如果ModUnionTableToZygoteAllocspace类的成员函数AddReference的返回值等于true,那么就将参数ref指向的对象添加到成员变量references_指向的一个vector中。
ModUnionTableToZygoteAllocspace类的成员函数AddReference的实现如下所示:
[cpp] view plaincopy
- class ModUnionTableToZygoteAllocspace : public ModUnionTableReferenceCache {
- public:
- explicit ModUnionTableToZygoteAllocspace(Heap* heap) : ModUnionTableReferenceCache(heap) {}
-
- bool AddReference(const mirror::Object / obj /, const mirror::Object ref) {
- const std::vector<space::ContinuousSpace*>& spaces = GetHeap()->GetContinuousSpaces();
- typedef std::vector<space::ContinuousSpace*>::const_iterator It;
- for (It it = spaces.begin(); it != spaces.end(); ++it) {
- if ((*it)->Contains(ref)) {
- return (*it)->IsDlMallocSpace();
- }
- }
- // Assume it points to a large object.
- // TODO: Check.
- return true;
- }
- };
这个函数定义在文件art/runtime/gc/accounting/mod_union_table-inl.h中。
ModUnionTableToZygoteAllocspace类的成员函数AddReference检查参数ref指向的对象,如果它位于一个Continous Space中,并且这个Continuous Space是一个DlMallocSpace,那么就返回true,以表示参数ref指向的对象是一个在Zygote Space和Allocation Space上分配的对象。注意,Zygote Space和Allocation Space都是属于DlMallocSpace。
另一方面,如果参数ref指向的对象不是位于Continous Space,那么它就肯定是位于Large Object Space中,这时候也需要ModUnionTableToZygoteAllocspace类的成员函数AddReference也是返回true,以表示该对象也需要进行处理。
这样,等到ModUnionTableToZygoteAllocspace类的成员函数Update执行完毕,那些直接被Dirty Card引用的对象就记录在其成员变量references_描述的一个Safe Map中了,接下来还需要继续调用ModUnionTableToZygoteAllocspace类的成员函数MarkReferences对保存在上述Safe Map中的对象进行递归标记。
ModUnionTableToZygoteAllocspace类的成员函数MarkReferences是从父类ModUnionTableReferenceCache继承下来的,它的实现如下所示:
[cpp] view plaincopy
- void ModUnionTableReferenceCache::MarkReferences(collector::MarkSweep* mark_sweep) {
- ......
-
- for (const auto& ref : references_) {
- for (const auto& obj : ref.second) {
- mark_sweep->MarkRoot(obj);
- ......
- }
- }
- ......
- }
这个函数定义在文件art/runtime/gc/accounting/mod_union_table.cc中。
ModUnionTableReferenceCache类的成员函数MarkReferences主要就是对保存在成员变量references_描述的一个Safe Map中的对象通过调用参数mark_sweep描述的一个Mark Sweep进行递归标记。
这样,等ModUnionTableReferenceCache类的成员函数MarkReferences执行完毕,所有被与Image Space对应的Dirty Card引用的对象都被递归标记完毕了。
接下来我们再来分析被与Zygote Space对应的Dirty Card引用的对象递归标记的过程。如前所述,这是通过调用ModUnionTableCardCache类的成员函数Update和MarkReferences来实现的。
ModUnionTableCardCache类的成员函数Update是一个空实现,它也什么也不做,因此我们主要就是分析ModUnionTableCardCache类的成员函数MarkReferences的实现,如下所示:
[cpp] view plaincopy
- // Mark all references to the alloc space(s).
- void ModUnionTableCardCache::MarkReferences(collector::MarkSweep* mark_sweep) {
- CardTable* cardtable = heap->GetCardTable();
- ModUnionScanImageRootVisitor visitor(mark_sweep);
- space::ContinuousSpace* space = nullptr;
- SpaceBitmap* bitmap = nullptr;
- for (const byte* card_addr : clearedcards) {
- auto start = reinterpret_cast(card_table->AddrFromCard(card_addr));
- auto end = start + CardTable::kCardSize;
- auto obj_start = reinterpret_cast<Object*>(start);
- if (UNLIKELY(space == nullptr || !space->Contains(obj_start))) {
- space = heap_->FindContinuousSpaceFromObject(obj_start, false);
- DCHECK(space != nullptr);
- bitmap = space->GetLiveBitmap();
- DCHECK(bitmap != nullptr);
- }
- bitmap->VisitMarkedRange(start, end, visitor);
- }
- }
这个函数定义在文件art/runtime/gc/accounting/mod_union_table.cc中。
ModUnionTableCardCache类的成员变量cleared_cards描述的是一具CarSet,这个CardSet保存了与Zygote Space对应的Card Table中的Dirty Card。ModUnionTableCardCache类的成员函数MarkReferences遍历与这些Dirty Card对应的每一个对象,并且调用ModUnionScanImageRootVisitor类的操作符重载成员函数()对这些对象进行处理。
ModUnionScanImageRootVisitor类的操作符重载成员函数()的实现如下所示:
[cpp] view plaincopy
- class ModUnionScanImageRootVisitor {
- public:
- explicit ModUnionScanImageRootVisitor(collector::MarkSweep* const mark_sweep)
- : marksweep(mark_sweep) {}
-
- void operator()(const Object* root) const
- EXCLUSIVE_LOCKS_REQUIRED(Locks::heap_bitmaplock)
- SHARED_LOCKS_REQUIRED(Locks::mutatorlock) {
- DCHECK(root != NULL);
- marksweep->ScanRoot(root);
- }
-
- private:
- collector::MarkSweep* const marksweep;
- };
这个函数定义在文件art/runtime/gc/accounting/mod_union_table.cc中。
参数root描述的便是与Zygote Space对应的Dirty Card的对象,ModUnionScanImageRootVisitor类的操作符重载成员函数()通过调用成员变量mark_sweep_描述的一个Mark Sweep对象的成员函数ScanRoot对它进行递归标记。
从这里就可以看出,虽然我们说Heap类的成员变量zygote_mod_union_table_描述的ModUnionTableCardCache是用来描述在Zygote Space上分配的对象对在Allocation Space上分配的对象的引用,但是ModUnionTableCardCache类并没有像ModUnionTableToZygoteAllocspace一样对被引用对象所在的Space进行判断,而是不管在什么Space都进行标记,这样虽然不会造成逻辑错误,但是也会多做一些无用功。例如,如果被引用对象是位于Image Space上,由于Image Space在这种情况下是不进行回收的,那么对它们进行标记就没有意义。ART运行时实现了一个ModUnionTableToAllocspace类,它的实现就类似于ModUnionTableToZygoteAllocspace,不过只会对被引用对象是在Allocation Space上分配的才会进行递归标记。
这样,等ModUnionTableCardCache类的成员函数MarkReferences执行完毕,所有被与Zygote Space对应的Dirty Card引用的对象都被递归标记完毕了。
至此,Marking阶段对Card Table中的Dirty Card的处理就暂告一段落了,回到前面的MarkSweep类的成员函数MarkingPhase中,接下它还需要做的事情包括调用Heap类的成员函数SwapStacks交换Allocation Stack和Live Stack,以及调用MarkSweep类的成员函数MarkRoots、MarkThreadRoots、MarkNonThreadRoots、MarkConcurrentRoots和MarkReachableObjects来递归标记根集对象。
Heap类的成员函数SwapStacks的实现如下所示:
[cpp] view plaincopy
- void Heap::SwapStacks() {
- allocationstack.swap(livestack);
- }
这个函数定义在文件art/runtime/gc/heap.cc中。
Heap类的成员变量allocation_stack_和live_stack_指向的分别是ART运行时的Allocation Stack和Live Stack,Heap类的成员函数SwapStacks对它们进交换,以便后面Sticky Mark Sweep可以进行进一步处理。
接下来,我们再分用来标记根集对象的MarkSweep类的成员函数MarkRoots、MarkThreadRoots、MarkNonThreadRoots、MarkConcurrentRoots。
ART运行时的根集对象按照是否能够并行访问划分为两类进行标记,一类是可以需要在获取Locks类的静态成员变量mutator_lock_描述的一个读写锁下进行标记,而另一类不需要。Runtime类提供了两个成员函数VisitConcurrentRoots和VisitNonConcurrentRoots来完成这两个操作。
Runtime类的成员函数VisitConcurrentRoots的实现如下所示:
[cpp] view plaincopy
- void Runtime::VisitConcurrentRoots(RootVisitor visitor, void arg, bool only_dirty,
- bool clean_dirty) {
- interntable->VisitRoots(visitor, arg, only_dirty, clean_dirty);
- classlinker->VisitRoots(visitor, arg, only_dirty, clean_dirty);
- }
这个函数定义在文件art/runtime/runtime.cc中。
Runtime类的成员变量intern_table_指向的是一个InternTable对象,里面保存有ART运行时使用的字符串常量,另外一个成员变量class_linker_指向的是一个ClassLinker对象,里面保存有ART运行时加载的类对象以及内部使用的Dex Cache。关于Dex Cache,可以参考前面Android运行时ART执行类方法的过程分析一文。
Runtime类的成员函数VisitConcurrentRoots所做的事情就是将ART运行时使用的字符串常量、已经加载的类对象以及Dex Cache对象标记为根集对象。
Runtime类的成员函数VisitNonConcurrentRoots的实现如下所示:
[cpp] view plaincopy
- void Runtime::VisitNonConcurrentRoots(RootVisitor visitor, void arg) {
- threadlist->VisitRoots(visitor, arg);
- VisitNonThreadRoots(visitor, arg);
- }
这个函数定义在文件art/runtime/runtime.cc中。
Runtime类的成员变量thread_list_指向的是一个ThreadList对象,里面保存了所有的ART运行时线程,Runtime类的成员函数VisitNonConcurrentRoots通过调用这个ThreadList对象的成员函数VisitRoots来标记所有位于ART运行时线程的调用栈上的根集对象。对于调用栈上的根集对象的标记,可以参考前面Dalvik虚拟机垃圾收集(GC)过程分析一文,ART运行时和Dalivk虚拟机的实现原理都是差不多的,这里不再详述。
Runtime类的成员函数VisitNonConcurrentRoots还会调用另外一个成员函数VisitNonConcurrentRoots来标记那些不是位于ART运行时线程的调用栈上的根集对象,它的实现如下所示:
[cpp] view plaincopy
- void Runtime::VisitNonThreadRoots(RootVisitor visitor, void arg) {
- javavm->VisitRoots(visitor, arg);
- if (pre_allocatedOutOfMemoryError != NULL) {
- visitor(pre_allocatedOutOfMemoryError, arg);
- }
- visitor(resolutionmethod, arg);
- for (int i = 0; i < Runtime::kLastCalleeSaveType; i++) {
- visitor(callee_savemethods[i], arg);
- }
- }
这个函数定义在文件art/runtime/runtime.cc中。
不是位于ART运行时线程的调用栈上的根集对象包括:
A. 在JNI方法里面通过JNI接口创建的全局引用对象以及被PIN住的数组对象,这些对象保存在Runtime类的成员变量java_vm_描述的一个JavaVMExt对象中,通过调用它的成员函数VisitRoots即可将它们标记为根集对象。
B. Runtime类的成员pre_allocated_OutOfMemoryError_指向的一个OOM异常对象,直接通过参数visitor描述的一个RootVisitor将它标记为根集对象。
C. Runtime类内部使用的运行时方法对象,它们分别保存在成员变量resolution_method_和callee_save_methods_中,它们也是接通过参数visitor描述的一个RootVisitor将它标记为根集对象。。关于ART运行时的运行时方法,可以参考前面Android运行时ART执行类方法的过程分析一文。
此外,Runtime类还提供了另外一个成员函数VisitRoots,用来一次性标记所有的根集对象,如下所示:
[cpp] view plaincopy
- void Runtime::VisitRoots(RootVisitor visitor, void arg, bool only_dirty, bool clean_dirty) {
- VisitConcurrentRoots(visitor, arg, only_dirty, clean_dirty);
- VisitNonConcurrentRoots(visitor, arg);
- }
这个函数定义在文件art/runtime/runtime.cc中。
Runtime类的成员函数VisitRoots通过调用前面分析过的两个成员函数VisitConcurrentRoots和VisitNonConcurrentRoots来遍历当前ART运行时的所有根集对象。
回到MarkSweep类的成员函数MarkingPhase中,它先标记那些需要获取Locks类的静态成员变量mutator_lock_描述的一个读写锁的根集对象,然后再标记那些不需要获取该读写锁的根集对象,后者通过调用MarkSweep类的成员函数MarkConcurrentRoots来实现,如下所示:
[cpp] view plaincopy
- void MarkSweep::MarkConcurrentRoots() {
- timings_.StartSplit("MarkConcurrentRoots");
- // Visit all runtime roots and clear dirty flags.
- Runtime::Current()->VisitConcurrentRoots(MarkObjectCallback, this, false, true);
- timings_.EndSplit();
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数MarkConcurrentRoots调用的就是前面分析Runtime类的成员函数VisitConcurrentRoots来标记相应的根集对象,并且指定的标记函数为MarkSweep类的静态成员函数MarkObjectCallback。
MarkSweep类的静态成员函数MarkObjectCallback的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::MarkObjectCallback(const Object root, void arg) {
- ......
- MarkSweep mark_sweep = reinterpret_cast<MarkSweep>(arg);
- mark_sweep->MarkObjectNonNull(root);
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的静态成员函数MarkObjectCallback又是通过调用另外一个成员函数MarkObjectNonNull来对参数root描述的根集对象进行标记的。
MarkSweep类的成员函数MarkObjectNonNull的实现如下所示:
[cpp] view plaincopy
- inline void MarkSweep::MarkObjectNonNull(const Object* obj) {
- DCHECK(obj != NULL);
-
- if (IsImmune(obj)) {
- DCHECK(IsMarked(obj));
- return;
- }
-
- // Try to take advantage of locality of references within a space, failing this find the space
- // the hard way.
- accounting::SpaceBitmap* object_bitmap = current_markbitmap;
- if (UNLIKELY(!object_bitmap->HasAddress(obj))) {
- accounting::SpaceBitmap* newbitmap = heap->GetMarkBitmap()->GetContinuousSpaceBitmap(obj);
- if (LIKELY(new_bitmap != NULL)) {
- object_bitmap = new_bitmap;
- } else {
- MarkLargeObject(obj, true);
- return;
- }
- }
-
- // This object was not previously marked.
- if (!object_bitmap->Test(obj)) {
- object_bitmap->Set(obj);
- if (UNLIKELY(markstack->Size() >= markstack->Capacity())) {
- // Lock is not needed but is here anyways to please annotalysis.
- MutexLock mu(Thread::Current(), mark_stacklock);
- ExpandMarkStack();
- }
- // The object must be pushed on to the mark stack.
- markstack->PushBack(const_cast<Object*>(obj));
- }
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数MarkObjectNonNull首先是判断参数obj指定的对象是否在不回收范围内,这是通过调用MarkSweep类的成员函数IsImmune来判断的。GC的不回收范围,是前面通过调用MarkSweep类的成员函数BindBitmap来设置的。一旦参数obj指定的对象在不回收范围内,MarkSweep类的成员函数MarkObjectNonNull什么也不用做就返回了。
MarkSweep类的成员变量current_mark_bitmap_缓存的是Allocation Space对应的Mark Bitmap,这是通过前面分析的MarkSweep类的成员函数FindDefaultMarkBitmap来实现的。这个缓存的Mark Bitmap是为了避免每次标记对象时,都要去查找它对应的Mark Bitmap而设计的,这样可以提高标记对象的效率,因为大部分对象都是位于Allocation Space上的。
MarkSweep类的成员函数MarkObjectNonNull接下来就是判断成员变量current_mark_bitmap_指向的Mark Bitmap是否可以用来标记对象obj。如果不可以,就先在Continuous Space的Mark Bitmap中找到可以用来标记对象obj的Mark Bitmap。如果找不到,就说明该对象是在Large Object Space上分配的,因此就调用另外一个成员函数MarkLargeObject对它进行标记。
找到了可以用来标记对象obj的Mark Bitmap之后,就可以对对象obj进行处理了。如果对象obj之前已经被标记过了,那么就什么也不用做。否则的话,就调用SpaceBitmap类的成员函数Set对它进行标记,并且将它压入到MarkSweep类的成员变量mark_stack_描述的一个Mark Stack中,以表后面可以执行递归标记。
回到MarkSweep类的成员函数MarkingPhase中,对于那些需要获取Locks类的静态成员变量mutator_lock_描述的一个读写锁的根集对象的标记,分为非并行GC和并行GC两种情况考虑。
对于非并行GC,此时除了当前执行GC的线程之外,其它的ART运行时线程都已经被挂起,因此,这时候根集对象就只可以在当前执行GC的线程中进行标记。这是通过调用MarkSweep类的成员函数MarkRoots来实现的,如下所示:
[cpp] view plaincopy
- void MarkSweep::MarkRoots() {
- timings_.StartSplit("MarkRoots");
- Runtime::Current()->VisitNonConcurrentRoots(MarkObjectCallback, this);
- timings_.EndSplit();
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数MarkRoots通过调用前面分析过的Runtime类的成员函数VisitNonConcurrentRoots来遍历那些需要获取Locks类的静态成员变量mutator_lock_描述的一个读写锁的根集对象,并且也是通过调用前面分析过的MarkSweep类的静态成员函数MarkObjectCallback,对它们进行标记。
对并行GC。我们可以将那些需要获取Locks类的静态成员变量mutator_lock_描述的一个读写锁的根集对象划分为两类,一类是位于线程调用栈的,另一类是不位于线程调用栈的。对于不是位于线程调用栈的根集对象,在当前执行GC的线程中调用MarkSweep类的成员函数MarkNonThreadRoots来进行标记。
MarkSweep类的成员函数MarkNonThreadRoots的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::MarkNonThreadRoots() {
- timings_.StartSplit("MarkNonThreadRoots");
- Runtime::Current()->VisitNonThreadRoots(MarkObjectCallback, this);
- timings_.EndSplit();
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数MarkRoots通过调用前面分析过的Runtime类的成员函数VisitNonThreadRoots来遍历那些不是在线程调用栈的根集对象,并且也是通过调用前面分析过的MarkSweep类的静态成员函数MarkObjectCallback,对它们进行标记。
对于位于线程调用栈的根集对象的标记,可以做利用CPU的多核特性做一些并发优化。注意,这时候除了当前执行GC的线程可以运行之外,其它的ART运行时线程也是可以运行的。这样就可以让正在运行的ART运行时线程来并发标记各自那些位于调用栈上的根集对象。这个工作是通过调用MarkSweep类的成员函数MarkThreadRoots来实现的,如下所示:
[cpp] view plaincopy
- void MarkSweep::MarkThreadRoots(Thread* self) {
- MarkRootsCheckpoint(self);
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数MarkThreadRoots又是通过调用另外一个成员函数MarkRootsCheckpoint对调用栈上的根集对象进行并行标记的,后者的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::MarkRootsCheckpoint(Thread* self) {
- CheckpointMarkThreadRoots check_point(this);
- timings_.StartSplit("MarkRootsCheckpoint");
- ThreadList* thread_list = Runtime::Current()->GetThreadList();
- // Request the check point is run on all threads returning a count of the threads that must
- // run through the barrier including self.
- size_t barrier_count = thread_list->RunCheckpoint(&check_point);
- // Release locks then wait for all mutator threads to pass the barrier.
- // TODO: optimize to not release locks when there are no threads to wait for.
- Locks::heap_bitmaplock->ExclusiveUnlock(self);
- Locks::mutatorlock->SharedUnlock(self);
- ThreadState old_state = self->SetState(kWaitingForCheckPointsToRun);
- CHECK_EQ(old_state, kWaitingPerformingGc);
- gcbarrier->Increment(self, barrier_count);
- self->SetState(kWaitingPerformingGc);
- Locks::mutatorlock->SharedLock(self);
- Locks::heap_bitmaplock->ExclusiveLock(self);
- timings_.EndSplit();
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数MarkThreadRoots首先是创建一个类型为CheckpointMarkThreadRoots的Check Point,然后通过调用ThreadList类的成员函数RunCheckpoint将该Check Point提交给当前运行的ART运行时线程执行。
ThreadList类的成员函数RunCheckpoint返回时,只表示Check Point已经提交了,但是可能还没有全部执行。它的返回值barrier_count描述的是执行Check Point的ART运行时线程的个数。MarkSweep类的成员函数MarkThreadRoots接下来就需要调用成员变量gc_barrier_描述的一个Barrier对象的成员函数Increment来等待上述的barrier_count个ART运行时线程执行完毕刚才提交的Check Point。
在等待其它ART运行时线程执行Check Point之前,MarkSweep类的成员函数MarkThreadRoots会先释放当前线程之前获得的Locks类的静态成员变量heap_bitmap_lock_描述的一个读写锁的写访问,以及Locks类的静态成员变量mutator_lock_描述的一个读写锁的读访问。等到Check Point都执先完成之后,再重新获得上述的两个锁。
ThreadList类的成员函数RunCheckpoint的实现如下所示:
[cpp] view plaincopy
- size_t ThreadList::RunCheckpoint(Closure* checkpoint_function) {
- Thread* self = Thread::Current();
- ......
-
- std::vector<Thread*> suspended_count_modified_threads;
- size_t count = 0;
- {
- // Call a checkpoint function for each thread, threads which are suspend get their checkpoint
- // manually called.
- MutexLock mu(self, *Locks::thread_listlock);
- for (const auto& thread : list_) {
- if (thread != self) {
- for (;;) {
- if (thread->RequestCheckpoint(checkpoint_function)) {
- // This thread will run it's checkpoint some time in the near future.
- count++;
- break;
- } else {
- // We are probably suspended, try to make sure that we stay suspended.
- MutexLock mu2(self, *Locks::thread_suspend_countlock);
- // The thread switched back to runnable.
- if (thread->GetState() == kRunnable) {
- continue;
- }
- thread->ModifySuspendCount(self, +1, false);
- suspended_count_modified_threads.push_back(thread);
- break;
- }
- }
- }
- }
- }
-
- // Run the checkpoint on ourself while we wait for threads to suspend.
- checkpoint_function->Run(self);
-
- // Run the checkpoint on the suspended threads.
- for (const auto& thread : suspended_count_modified_threads) {
- if (!thread->IsSuspended()) {
- // Wait until the thread is suspended.
- uint64_t start = NanoTime();
- do {
- // Sleep for 100us.
- usleep(100);
- } while (!thread->IsSuspended());
- uint64_t end = NanoTime();
- // Shouldn't need to wait for longer than 1 millisecond.
- const uint64_t threshold = 1;
- if (NsToMs(end - start) > threshold) {
- LOG(INFO) << "Warning: waited longer than " << threshold
- << " ms for thread suspend\n";
- }
- }
- // We know for sure that the thread is suspended at this point.
- thread->RunCheckpointFunction();
- {
- MutexLock mu2(self, *Locks::thread_suspend_countlock);
- thread->ModifySuspendCount(self, -1, false);
- }
- }
-
- {
- // Imitate ResumeAll, threads may be waiting on Thread::resumecond since we raised their
- // suspend count. Now the suspendcount is lowered so we must do the broadcast.
- MutexLock mu2(self, *Locks::thread_suspend_countlock);
- Thread::resumecond->Broadcast(self);
- }
-
- // Add one for self.
- return count + suspended_count_modified_threads.size() + 1;
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
ThreadList类的成员函数RunCheckpoint的执行逻辑如下所示:
A. 遍历成员变量list_中的每一个ART运行时线程,并且通过调用它们的成员函数RequestCheckpoint分别向它们提交参数checkpoint_function的一个Check Point。如果能够成功提交,那么Thread类的成员函数RequestCheckpoint就返回true。如果不能成功提交,那么就可能是线程正处于挂起状态,这时候就要将线程的挂起计数器增加1,确保继续挂起,并且将该线程保存在变量suspended_count_modified_threads描述的一个向量中。不过,在增加线程的挂起计数器之前,线程有可能又切换为运行状态了,这时候就需要重新调用它的成员函数RequestCheckpoint向它重新提交数checkpoint_function的一个Check Point。
B. 当前线程是执行GC的线程,它也需要执行参数checkpoint_function的Check Point,直接调用它的成员函数Run来执行即可。
C. 接下来需要在当前线程代替那些处于挂起状态的线程执行提交给它们的、但是它们不能执行的Check Point,这是通过在当前线程调用Thread类的成员函数RunCheckpointFunction来完成的。执行完成之后,需要将这些线程的挂起计数器减少1。注意,必须要确保当前线程是在刚才保存在变量suspended_count_modified_threads描述的一个向量中的线程是在挂起状态下代替执行参数checkpoint_function的Check Point的,否则就会造成竞争条件。
D. 前面分析恢复ART运行时线程执行的时候提到,在增加了ART运行时线程的挂数计数器之后,需要通过Thread类的静态成员变量resume_cond_描述的一个条件变量唤醒被挂起的线程。这里由于也有同样的操作,因此也需要通过Thread类的静态成员变量resume_cond_描述的一个条件变量唤醒被挂起的线程。
E. 返回总共用来执行Check Point的ART运行时线程的个数。
注意,这时候那些成功接收了Check Point的ART运行时线程可能还没有执行Checkp Point。因此,ThreadList类的成员函数RunCheckpoint的调用方需要有一个等待的过程。
接下来,我们继续分析Thread类的成员函数RequestCheckpoint的实现,以便可以了解给一个线程提交Check Point的过程,它的实现如下所示:
[cpp] view plaincopy
- bool Thread::RequestCheckpoint(Closure* function) {
- CHECK(!ReadFlag(kCheckpointRequest)) << "Already have a pending checkpoint request";
- checkpointfunction = function;
- union StateAndFlags old_state_and_flags = state_andflags;
- // We must be runnable to request a checkpoint.
- old_state_and_flags.as_struct.state = kRunnable;
- union StateAndFlags new_state_and_flags = old_state_and_flags;
- new_state_and_flags.as_struct.flags |= kCheckpointRequest;
- int succeeded = android_atomic_cmpxchg(old_state_and_flags.as_int, new_state_and_flags.as_int,
- &state_andflags.as_int);
- return succeeded == 0;
- }
这个函数定义在文件art/runtime/thread.cc中。
Thread类的成员函数RequestCheckpoint首先将参数function描述的一个Check Point保存在成员变量checkpointfunction,然后尝试将线程的状态设置为kRunnable,并且将其标记位kCheckpointRequest设置为1。如果能成功修改线程的状态和标记位,那么就可以保证线程接下来可以执行保存在成员变量checkpoint_function_的Check Point。
前面分析ART运行时线程的挂起过程时提到,ART运行时线程在运行的过程中,会周期性地检查自己的挂起计数器和标志位,如果发现自己的kCheckpointRequest标记位被设置为1,那么它就知道自己有一个Check Point需要等待执行,于是就会调用Thread类的成员函数RunCheckpointFunction来执行该Check Point。
Thread类的成员函数RunCheckpointFunction的实现如下所示:
[cpp] view plaincopy
- void Thread::RunCheckpointFunction() {
- ......
- checkpointfunction->Run(this);
- ......
- }
这个函数定义在文件art/runtime/thread.cc中。
Thread类的成员函数RunCheckpointFunction通过调用成员变量checkpoint_function_指向的一个Check Point的成员函数Run来执行对应的Check Point。在我们这个情景中,Thread类的成员变量checkpoint_function_指向的是一个CheckpointMarkThreadRoots对象,它的成员函数Run的实现如下所示:
[cpp] view plaincopy
- class CheckpointMarkThreadRoots : public Closure {
- public:
- explicit CheckpointMarkThreadRoots(MarkSweep* mark_sweep) : marksweep(mark_sweep) {}
-
- virtual void Run(Thread* thread) NO_THREAD_SAFETY_ANALYSIS {
- ......
- Thread* self = Thread::Current();
- ......
- thread->VisitRoots(MarkSweep::MarkRootParallelCallback, marksweep);
- ......
- marksweep->GetBarrier().Pass(self);
- }
-
- private:
- MarkSweep* marksweep;
- };
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
当前线程通过调用Thread类的成员函数VisitRoots来遍历调用栈上的根集对象,并且通过MarkSweep类的静态成员函数MarkRootParallelCallback对它们进行标记。标记完成后,再调用在前面分析MarkSweep类的成员函数MarkRootsCheckpoint时提到的Barrier对象的成员Pass,以便可以通知有一个线程执行完成自己的Check Point了,这样就可以使得正在等待所有ART运行时线程都执行完成自己的Check Point的GC线程可以被唤醒继续往前执行。
MarkSweep类的静态成员函数MarkRootParallelCallback的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::MarkRootParallelCallback(const Object root, void arg) {
- ......
- reinterpret_cast<MarkSweep*>(arg)->MarkObjectNonNullParallel(root);
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的静态成员函数MarkRootParallelCallback通过调用另外一个成员函数MarkObjectNonNullParallel来标记参数root描述的根集对象,后者的实现如下所示:
[cpp] view plaincopy
- inline void MarkSweep::MarkObjectNonNullParallel(const Object* obj) {
- ......
- if (MarkObjectParallel(obj)) {
- MutexLock mu(Thread::Current(), mark_stacklock);
- if (UNLIKELY(markstack->Size() >= markstack->Capacity())) {
- ExpandMarkStack();
- }
- // The object must be pushed on to the mark stack.
- markstack->PushBack(const_cast<Object*>(obj));
- }
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数MarkObjectNonNullParallel又调用另外一个成员函数MarkObjectParallel来标记参数obj描述的根集对象。如果标记成功,那么就将它压入到成员变量mark_stack_描述的一个Mark Stack中,以便后面可以执行递归标记。
MarkSweep类的成员函数MarkObjectParallel的实现如下所示:
[cpp] view plaincopy
- inline bool MarkSweep::MarkObjectParallel(const Object* obj) {
- DCHECK(obj != NULL);
-
- if (IsImmune(obj)) {
- DCHECK(IsMarked(obj));
- return false;
- }
-
- // Try to take advantage of locality of references within a space, failing this find the space
- // the hard way.
- accounting::SpaceBitmap* object_bitmap = current_markbitmap;
- if (UNLIKELY(!object_bitmap->HasAddress(obj))) {
- accounting::SpaceBitmap* newbitmap = heap->GetMarkBitmap()->GetContinuousSpaceBitmap(obj);
- if (new_bitmap != NULL) {
- object_bitmap = new_bitmap;
- } else {
- // TODO: Remove the Thread::Current here?
- // TODO: Convert this to some kind of atomic marking?
- MutexLock mu(Thread::Current(), large_objectlock);
- return MarkLargeObject(obj, true);
- }
- }
-
- // Return true if the object was not previously marked.
- return !object_bitmap->AtomicTestAndSet(obj);
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数MarkObjectParallel的实现与前面分析的另外一个成员函数MarkObjectNonNull是差不多的,因此这里不再详述。
现在,所有的根集对象终于都标记完成了。回到前面的MarkSweep类的成员函数MarkingPhase中,最后需要做的事情是递归标记那些根集对象递归引用的其它对象,这是通过调用MarkSweep类的成员函数MarkReachableObjects来实现的,如下所示:
[cpp] view plaincopy
- void MarkSweep::MarkReachableObjects() {
- // Mark everything allocated since the last as GC live so that we can sweep concurrently,
- // knowing that new allocations won't be marked as live.
- timings_.StartSplit("MarkStackAsLive");
- accounting::ObjectStack* livestack = heap->GetLiveStack();
- heap->MarkAllocStack(heap->allocspace->GetLiveBitmap(),
- heap_->large_objectspace->GetLiveObjects(), live_stack);
- live_stack->Reset();
- timings_.EndSplit();
- // Recursively mark all the non-image bits set in the mark bitmap.
- RecursiveMark();
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数MarkReachableObjects首先会将Live Stack的对象全部进行标记。这里的Live Stack其实就是之前的Allocation Stack,也就是说,Mark Sweep不会对上次GC以后分配的对象进行垃圾回收。Partial Mark Sweep也是通过父类MarkSweep类的成员函数MarkReachableObjects来递归标记根集对象引用的对象的,也就是说,Mark Sweep也不会对上次GC以后分配的对象进行垃圾回收。由于Sticky Mark Sweep刚好相反,它要对上次GC以后分配的对象进行垃圾回收,因此,它就必须要重写MarkSweep类的成员函数MarkReachableObjects。
MarkSweep类的成员函数MarkReachableObjects接着再调用MarkSweep类的成员函数RecursiveMark对根集对象引用的其它对象进行递归标记,它的实现如下所示:
[cpp] view plaincopy
- // Populates the mark stack based on the set of marked objects and
- // recursively marks until the mark stack is emptied.
- void MarkSweep::RecursiveMark() {
- base::TimingLogger::ScopedSplit split("RecursiveMark", &timings_);
- ......
-
- if (kUseRecursiveMark) {
- const bool partial = GetGcType() == kGcTypePartial;
- ScanObjectVisitor scan_visitor(this);
- auto* self = Thread::Current();
- ThreadPool* threadpool = heap->GetThreadPool();
- size_t thread_count = GetThreadCount(false);
- const bool parallel = kParallelRecursiveMark && thread_count > 1;
- markstack->Reset();
- for (const auto& space : GetHeap()->GetContinuousSpaces()) {
- if ((space->GetGcRetentionPolicy() == space::kGcRetentionPolicyAlwaysCollect) ||
- (!partial && space->GetGcRetentionPolicy() == space::kGcRetentionPolicyFullCollect)) {
- current_markbitmap = space->GetMarkBitmap();
- ......
- if (parallel) {
- // We will use the mark stack the future.
- // CHECK(markstack->IsEmpty());
- // This function does not handle heap end increasing, so we must use the space end.
- uintptr_t begin = reinterpret_cast(space->Begin());
- uintptr_t end = reinterpret_cast(space->End());
- atomicfinger = static_cast(0xFFFFFFFF);
-
- // Create a few worker tasks.
- const size_t n = thread_count * 2;
- while (begin != end) {
- uintptr_t start = begin;
- uintptr_t delta = (end - begin) / n;
- delta = RoundUp(delta, KB);
- if (delta < 16 * KB) delta = end - begin;
- begin += delta;
- auto* task = new RecursiveMarkTask(thread_pool, this, current_markbitmap, start,
- begin);
- thread_pool->AddTask(self, task);
- }
- thread_pool->SetMaxActiveWorkers(thread_count - 1);
- thread_pool->StartWorkers(self);
- thread_pool->Wait(self, true, true);
- thread_pool->StopWorkers(self);
- } else {
- // This function does not handle heap end increasing, so we must use the space end.
- uintptr_t begin = reinterpret_cast(space->Begin());
- uintptr_t end = reinterpret_cast(space->End());
- current_markbitmap->VisitMarkedRange(begin, end, scan_visitor);
- }
- }
- }
- }
- ProcessMarkStack(false);
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
如果常量kUseRecursiveMark和kParallelRecursiveMark的值均设置为true,并且ART运行时在启动时创建的用于执行并发GC的线程个数thread_count大于1,那么对于Allocation Space以及不是kGcTypePartial类型的GC下的Zygote Space,将采用多线程并发递归标记那些被根集对象直接或者间接引用的其它对象。
假设一个Space的大小为(end - begin),用来执行并发标记的线程的个数为thread_count,那么就将整个Space的标记任务划分为(end - begin) / (thread_count * 2)个子任务。每一个子任务都封装成一个RecursiveMarkTask对象,通过调用ThreadPool类的成员函数AddTask添加到线程池中去。
接着再通过ThreadPool类的成员函数SetMaxActiveWorkers将线程池用于执行任务的线程个数设置(thread_count - 1)。为什么不是设置为thread_count呢?这是因为当前线程也是属于执行GC任务的线程之一,因此就只需要从线程池中抽取(thread_count - 1)个线程出来就行了。另外,调用MarkSweep类的成员函数GetThreadCount获得线程池的线程个数,如果指定的参数为false,表示要获取的是在GC并发阶段可以用来执行GC任务的线程的个数,对应于ART运运时启动选项-XX:ConcGCThreads指定的线程个数。如果指定的参数为true,则表示要获取的是在GC暂停阶段可以用来执行GC任务的线程的个数,对应于ART运运时启动选项-XX:ParallelGCThreads指定的线程个数。
最后就调用ThreadPool类的成员函数StartWorkers启动线程池执行任务,并且通过调用ThreadPool类的另外一个成员函数Wait来让当前线程去执行线程池的任务,并且等待其它线程执行完成任务。
如果一个Space不能满足上述的并发标记条件,那么就只能在当前线程中递归标记根集对象,这是通过调用SpaceBitmap类的成员函数VisitMarkedRange来完成的,并且通过变量scan_visitor描述的一个ScanObjectVisitor对象来执行具体的标记任务。
由于在前面的标记过程中,可能又会有新的对象被压入到Mark Stack中,因此,MarkSweep类的成员函数RecursiveMark最后还需要调用另外一个成员函数ProcessMarkStack来检查Mark Stack是否不为空。如果不为空,那么就需要递归标记下去。
这样,当常量kUseRecursive等于true,MarkMarkSweep类的成员函数RecursiveMark实际上既需要通过线程池来并发执行RecursiveMarkTask,也需要通过调用MarkSweep类的成员函数ProcessMarkStack来执行在单线程中执行递归标记根集的任务,而当kUseRecursive等于false,就只会调用MarkSweep类的成员函数ProcessMarkStack来执行在单线程中执行递归标记根集的任务。接下来我们就这两种递归标记根集对象的过程。
并发递归标记根集对象的过程是通过在线程池中执行RecursiveMarkTask来完成的,也就是调用RecursiveMarkTask类的成员函数Run来完成的,它的实现如下所示:
[cpp] view plaincopy
- class RecursiveMarkTask : public MarkStackTask {
- ......
-
- // Scans all of the objects
- virtual void Run(Thread* self) NO_THREAD_SAFETY_ANALYSIS {
- ScanObjectParallelVisitor visitor(this);
- bitmap->VisitMarkedRange(begin, end_, visitor);
- // Finish by emptying our local mark stack.
- MarkStackTask::Run(self);
- }
- };
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
RecursiveMarkTask类的成员函数Run首先是通过调用成员变量bitmap_指向的一个SpaceBitmap对象的成员函数VisitMarkedRange来遍历成员变量begin_和end_限定范围的被标记对象,即根集对象,并且通过调用ScanObjectParallelVisitor类的操作符重载函数()对它们进行处理,接着再调用父类MarkStackTask的成员函数Run来递归标记上述的根集对象。
ScanObjectParallelVisitor类的操作符重载函数()的实现如下所示:
[cpp] view plaincopy
- template
- class MarkStackTask : public Task {
- ......
-
- protected:
- class ScanObjectParallelVisitor {
- public:
- explicit ScanObjectParallelVisitor(MarkStackTask* chunk_task) ALWAYS_INLINE
- : chunktask(chunk_task) {}
-
- void operator()(const Object* obj) const {
- MarkSweep* mark_sweep = chunktask->marksweep;
- mark_sweep->ScanObjectVisit(obj,
- [mark_sweep, this](const Object / obj /, const Object ref,
- const MemberOffset& / offset /, bool / is_static /) ALWAYS_INLINE {
- if (ref != nullptr && mark_sweep->MarkObjectParallel(ref)) {
- ......
- chunktask->MarkStackPush(ref);
- }
- });
- }
-
- private:
- MarkStackTask* const chunktask;
- };
-
- .....
-
- void MarkStackPush(const Object* obj) ALWAYS_INLINE {
- if (UNLIKELY(mark_stackpos == kMaxSize)) {
- // Mark stack overflow, give 1/2 the stack to the thread pool as a new work task.
- mark_stackpos /= 2;
- auto* task = new MarkStackTask(threadpool, marksweep, kMaxSize - mark_stackpos,
- markstack + mark_stackpos);
- threadpool->AddTask(Thread::Current(), task);
- }
- ......
- markstack[mark_stackpos++] = obj;
- }
-
- ......
- };
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
ScanObjectParallelVisitor类的操作符重载函数()调用MarkSweep类的成员函数ScanObjectVisit遍历参数obj指向的一个对象的引用类型的成员变量引用的对象,并且通过一个闭包函数来处理这些引用对象。闭包函数又是通过调用我们前面分析过的MarkSweep类的成员函数MarkObjectParallel来对对象obj的引用类型的成员变量引用的对象。如果这些引用对象之前没有被标记过,那么MarkSweep类的成员函数MarkObjectParallel就会返回true,这时候闭包函数将会调用MarkStackTask类的成员函数MarkStack将引用对象压入到其成员变量mark_stack_描述的一个Mark Stack去。注意,这个Mark Stack是MarkStackTask类在内部使用的一个Stack,它与ART运行时在启动时创建的Mark Stack是不一样的。
此外,在将一个对象压入到MarkStackTask类的成员变量mark_stack_描述的一个Mark Stack去之前,如果这个Mark Stack已经满了,那么就会将这个Mark Stack的后半部分还未来得及递归标记的对象封装成一个MarkStackTask添加到线程池去执行递归标记。这样就可以将Mark Stack的大小减半,从而得以将参数obj指向的对象压入到Mark Stack中。
回到RecursiveMarkTask类的成员函数Run中,它最后通过调过调用父类MarkStackTask的成员函数Run来递归标记保存其成员变量mark_stack_描述的Mark Stack中的对象,它的实现如下所示:
[cpp] view plaincopy
- template
- class MarkStackTask : public Task {
- ......
-
- // Scans all of the objects
- virtual void Run(Thread* self) {
- ScanObjectParallelVisitor visitor(this);
- // TODO: Tune this.
- static const size_t kFifoSize = 4;
- BoundedFifoPowerOfTwo<const Object*, kFifoSize> prefetch_fifo;
- for (;;) {
- const Object* obj = NULL;
- if (kUseMarkStackPrefetch) {
- while (mark_stackpos != 0 && prefetch_fifo.size() < kFifoSize) {
- const Object* obj = markstack[--mark_stackpos];
- DCHECK(obj != NULL);
- __builtin_prefetch(obj);
- prefetch_fifo.push_back(obj);
- }
- if (UNLIKELY(prefetch_fifo.empty())) {
- break;
- }
- obj = prefetch_fifo.front();
- prefetch_fifo.pop_front();
- } else {
- if (UNLIKELY(mark_stackpos == 0)) {
- break;
- }
- obj = markstack[--mark_stackpos];
- }
- DCHECK(obj != NULL);
- visitor(obj);
- }
- }
- };
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
如果常量kUseMarkStackPrefetch的值定义为true,那么MarkStackTask的成员函数Run在递归遍历其成员变量mark_stack_描述的一个Mark Stack的对象,会通过函数__builtin_prefetch来预读取接下来要遍历的对象,这样就可以加快从Mark Stack中获取下一个要遍历的对象的速度。否则的话,就每次都正常地从Mark Stack读取下一个要遍历的对象。
对于从Mark Stack读取出来的对象,都是通过前面分析的ScanObjectParallelVisitor类的操作符重载成员函数()来进行标记的。由于ScanObjectParallelVisitor类的操作符重载成员函数()又会将它标记的对象引用的其它对象压入到MarkStackTask的成员变量mark_stack_描述的Mark Stack中,因此,MarkStackTask的成员函数Run就会一直执行,直到上述的Mark Stack为空为止。通过这种方式,就完成了递归标记根集对象的过程。
这样,并发递归标记根集对象的过程就分析完成了,接下来再来看非并发递归标记根集对象的过程,这是通过调用MarkSweep类的成员函数ProcessMarkStack来实现的,如下所示:
[cpp] view plaincopy
- void MarkSweep::ProcessMarkStack(bool paused) {
- timings_.StartSplit("ProcessMarkStack");
- size_t thread_count = GetThreadCount(paused);
- if (kParallelProcessMarkStack && thread_count > 1 &&
- markstack->Size() >= kMinimumParallelMarkStackSize) {
- ProcessMarkStackParallel(thread_count);
- } else {
- // TODO: Tune this.
- static const size_t kFifoSize = 4;
- BoundedFifoPowerOfTwo<const Object*, kFifoSize> prefetch_fifo;
- for (;;) {
- const Object* obj = NULL;
- if (kUseMarkStackPrefetch) {
- while (!markstack->IsEmpty() && prefetch_fifo.size() < kFifoSize) {
- const Object* obj = markstack->PopBack();
- DCHECK(obj != NULL);
- __builtin_prefetch(obj);
- prefetch_fifo.push_back(obj);
- }
- if (prefetch_fifo.empty()) {
- break;
- }
- obj = prefetch_fifo.front();
- prefetch_fifo.pop_front();
- } else {
- if (markstack->IsEmpty()) {
- break;
- }
- obj = markstack->PopBack();
- }
- DCHECK(obj != NULL);
- ScanObject(obj);
- }
- }
- timings_.EndSplit();
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
如果常量kParallelProcessMarkStack的值等于true,并且ART运行时启动时创建的用来执行并发GC任务的线程池包含的线程个数大于1,以及此时ART运行时的Mark Stack包含的未处理对象的个数大于常量kMinimumParallelMarkStackSize定义的值,那么MarkSweep类的成员函数ProcessMarkStack就会通过调用另外一个成员函数ProcessMarkStackParallel来并发递归标记Mark Stack中的对象。
否则的话,就只会在当前线程中对ART运行时的Mark Stack中的对象进行递归标记。在遍历保存在ART运行时的Mark Stack中的对象时候,同样使用了前面提到的预读取技术,这样就可以加快从ART运行时的Mark Stack中读取下一个要遍历的对象的速度。同时,对于保存在ART运行时的Mark Stack中的每一个对象,都是通过调用MarkSweep类的成员函数ScanObject进行标记的。MarkSweep类的成员函数ScanObject在标记一个对象的时候,同时也会将该对象引用的其它的还没有被标记的对象压入到ART运行时的Mark Stack中,这样,上述的递归标记过程就会一直执行下去直到ART运行时的Mark Stack为空为止。
接下来我们再来看MarkSweep类的成员函数ProcessMarkStackParallel的实现,以便可以了解它是如何并发递归标记保存在ART运行时的Mark Stack中的对象的,它的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::ProcessMarkStackParallel(size_t thread_count) {
- Thread* self = Thread::Current();
- ThreadPool* thread_pool = GetHeap()->GetThreadPool();
- const size_t chunk_size = std::min(markstack->Size() / thread_count + 1,
- static_cast(MarkStackTask::kMaxSize));
- CHECK_GT(chunk_size, 0U);
- // Split the current mark stack up into work tasks.
- for (mirror::Object it = markstack->Begin(), end = markstack->End(); it < end; ) {
- const size_t delta = std::min(static_cast(end - it), chunk_size);
- thread_pool->AddTask(self, new MarkStackTask(thread_pool, this, delta,
- const_cast<const mirror::Object**>(it)));
- it += delta;
- }
- thread_pool->SetMaxActiveWorkers(thread_count - 1);
- thread_pool->StartWorkers(self);
- thread_pool->Wait(self, true, true);
- thread_pool->StopWorkers(self);
- markstack->Reset();
- CHECK_EQ(work_chunkscreated, work_chunksdeleted) << " some of the work chunks were leaked";
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数ProcessMarkStackParallel并发递归标记ART运行时的Mark Stack的方法与前面分析的MarkSweep类的成员函数RecursiveMark并发递归一个Space的根集对象的方法是类似的,只不过前者是对Mark Stack进行任务划分,而后者是对Space进行任务划分,两者划分出来的都是通过线程池来执行的。
这样,递归标记根集对象的过程也分析完成了。不过,这个过程只适用于Mark Sweep和Partial Mark Sweep。对于Sticky Mark Sweep,前面提到,它必须要重写了父类MarkSweep的成员函数MarkReachableObjects,以便可以对上次GC以来分配的对象进行垃圾回收。
StickyMarkSweep类的成员函数MarkReachableObjects的实现如下所示:
[cpp] view plaincopy
- void StickyMarkSweep::MarkReachableObjects() {
- // All reachable objects must be referenced by a root or a dirty card, so we can clear the mark
- // stack here since all objects in the mark stack will get scanned by the card scanning anyways.
- // TODO: Not put these objects in the mark stack in the first place.
- markstack->Reset();
- RecursiveMarkDirtyObjects(false, accounting::CardTable::kCardDirty - 1);
- }
这个函数定义在文件art/runtime/gc/collector/sticky_mark_sweep.cc中。
前面虽然我们说,在GC的Marking阶段,要标记的对象包括根集对象,以及根集对象可达的对象,但是由于Partial Mark Sweep和Sticky Mark Sweep的存在,从更广义来说,在GC的Marking阶段,要标记的对象包括根集对象,以及根集对象和Dirty Card可达的对象。
对于Sticky Mark Sweep来说,在调用StickyMarkSweep类的成员函数MarkReachableObjects之前,根集对象已经标记好了,并且Dirty Card也已经老化处理过了,但是它们可达的对象还没有处理。此外,这时候ART运行时的Mark Stack记录了根集对象直接引用的对象。理论上说,我们需要继续递归标记Mark Stack中的对象,以及Dirty Card引用的对象。但是这里却没有这样做,而是将Mark Stack清空,只递归标记Dirty Card可达的对象。为什么可以这样做呢?
前面我们在分析Heap类的成员函数ClearCards时提到,ART运行时的Card Table在运行期间是一直使用的,也就是它一直记录着上次GC以来那些修改了引用类型的成员变量的对象。现在考虑Sticky Mark Sweep,它要回收的是Allocation Stack的垃圾对象,并且在标记开始的时候,Image Space、Zygote Space和Allocation Space上次GC后存活下来的对象都已经被标记过了。这时候被标记的根集对象,可以划分为有引用类型和没有引用类型成员变量两类。
对于有引用类型成员变量的根集对象,它们在设置这些成员变量的时候,会被记录在Card Table中,即与它们对应的Card是Dirty的。因此,我们就可以在递归标记Dirty Card引用的对象的时候,把这些有引用类型成员变量的根集对象也顺带递归标记了。
对于没有引用类型成员变量的根集对象,只需要标记好它们自己就行了,不用递归标记它们引用的对象。也就是说,这一类根集对象已经在调用StickyMarkSweep类的成员函数MarkReachableObjects之前处理好了。
因此,StickyMarkSweep类的成员函数MarkReachableObjects就可以在递归标记Dirty Card引用的对象之前,将ART运行时的Mark Stack清空。那为什么Mark Sweep和Partial Mark Sweep又不可以这样做呢?
回忆前面分析的Heap类的成员函数UpdateAndMarkModUnion,对于Sticky Mark Sweep,什么也没有做,但是Mark Sweep和Partial Mark Sweep却对Dirty Card直接引用的对象进行了标记。在标记的过程中,ART运行时的Mark Stack也记录了这些直接被Dirty Card引用的对象引用的其它对象。也就是说,对于Mark Sweep和Partial Mark Sweep来说,此时ART运行时的Mark Stack包含了根集对象和Dirty Card可直达的对象,因此就不能将Mark Stack清空。
对于Sticky Mark Sweep,由于此时Dirty Card只被老化处理过,而Dirty Card引用的对象还没有被标记过,因此,这时候需要做的就是递归标记那些值等于DIRTY和(DIRTY - 1)的Card,这是通过调用从父类MarkSweep继承下来的成员函数RecursiveMarkDirtyObjects来实现的。
MarkSweep类的成员函数RecursiveMarkDirtyObjects的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::RecursiveMarkDirtyObjects(bool paused, byte minimum_age) {
- ScanGrayObjects(paused, minimum_age);
- ProcessMarkStack(paused);
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数RecursiveMarkDirtyObjects首先是调用成员函数ScanGrayObjects标记值大于等于minimum_age的Dirty Card,也就是值大于等于(DIRTY - 1)的Card引用的对象。由于在标记这些对象的过程中,可能会新的对象被压入到ART运行时的Mark Stack中,因此接下来还要继续调用前面已经分析过的MarkSweep类的成员函数ProcessMarkStack来递归标记它们。
接下来我们就继续分析MarkSweep类的成员函数ScanGrayObjects的实现,如下所示:
[cpp] view plaincopy
- void MarkSweep::ScanGrayObjects(bool paused, byte minimum_age) {
- accounting::CardTable* card_table = GetHeap()->GetCardTable();
- ThreadPool* thread_pool = GetHeap()->GetThreadPool();
- size_t thread_count = GetThreadCount(paused);
- // The parallel version with only one thread is faster for card scanning, TODO: fix.
- if (kParallelCardScan && thread_count > 0) {
- Thread* self = Thread::Current();
- // Can't have a different split for each space since multiple spaces can have their cards being
- // scanned at the same time.
- timings_.StartSplit(paused ? "(Paused)ScanGrayObjects" : "ScanGrayObjects");
- // Try to take some of the mark stack since we can pass this off to the worker tasks.
- const Object mark_stack_begin = const_cast<const Object>(markstack->Begin());
- const Object mark_stack_end = const_cast<const Object>(markstack->End());
- const size_t mark_stack_size = mark_stack_end - mark_stack_begin;
- // Estimated number of work tasks we will create.
- const size_t mark_stack_tasks = GetHeap()->GetContinuousSpaces().size() * thread_count;
- DCHECK_NE(mark_stack_tasks, 0U);
- const size_t mark_stack_delta = std::min(CardScanTask::kMaxSize / 2,
- mark_stack_size / mark_stack_tasks + 1);
- size_t ref_card_count = 0;
- cardsscanned = 0;
- for (const auto& space : GetHeap()->GetContinuousSpaces()) {
- byte* card_begin = space->Begin();
- byte* card_end = space->End();
- // Calculate how many bytes of heap we will scan,
- const size_t address_range = card_end - card_begin;
- // Calculate how much address range each task gets.
- const size_t card_delta = RoundUp(address_range / thread_count + 1,
- accounting::CardTable::kCardSize);
- // Create the worker tasks for this space.
- while (card_begin != card_end) {
- // Add a range of cards.
- size_t addr_remaining = card_end - card_begin;
- size_t card_increment = std::min(card_delta, addr_remaining);
- // Take from the back of the mark stack.
- size_t mark_stack_remaining = mark_stack_end - mark_stack_begin;
- size_t mark_stack_increment = std::min(mark_stack_delta, mark_stack_remaining);
- mark_stack_end -= mark_stack_increment;
- markstack->PopBackCount(static_cast(mark_stack_increment));
- DCHECK_EQ(mark_stack_end, markstack->End());
- // Add the new task to the thread pool.
- auto* task = new CardScanTask(thread_pool, this, space->GetMarkBitmap(), card_begin,
- card_begin + card_increment, minimum_age,
- mark_stack_increment, mark_stack_end);
- thread_pool->AddTask(self, task);
- card_begin += card_increment;
- }
-
- ......
- }
- thread_pool->SetMaxActiveWorkers(thread_count - 1);
- thread_pool->StartWorkers(self);
- thread_pool->Wait(self, true, true);
- thread_pool->StopWorkers(self);
- ......
- } else {
- for (const auto& space : GetHeap()->GetContinuousSpaces()) {
- ......
- ScanObjectVisitor visitor(this);
- card_table->Scan(space->GetMarkBitmap(), space->Begin(), space->End(), visitor, minimum_age);
- ......
- }
- }
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
如果常量kParallelCardScan的值设置为true,并且ART运行时启动过程中创建的用于执行并行GC任务的线程池包含的线程个数大于0,那么就采用并发的方法递归标记值Card Table中值等于DIRTY和(DIRTY - 1)的Card引用的对象。否则的话,就在当前线程中调用CardTable类的成员函数Scan来标记值Card Table中值等于DIRTY和(DIRTY - 1)的Card引用的对象。
使用并发方法递归标记Dirty Card引用的对象时,按照Card的大小和可用于执行并发GC任务的线程数来划分子任务。划分后每一个子任务都使用一个CardScanTask来描述。CardScanTask除了能够用来递归标记Dirty Card引用的对象之外,还能同时递归标记Mark Stack中的对象。Mark Stack的递归标记任务是按照Card的大小、可用于执行并发GC任务的线程数和Mark Stack的大小来划分的。CardScanTask任务划分完成之后,就将它们添加到线程池中去并发执行。它们的执行过程与我们前面分析的RecursiveMarkTask任务的并发执行过程是类似的,因此这里就不再深入分析下去。
这样,Sticky Mark Sweep递归标记根集对象和Dirty Card引用的对象的过程也分析完成了。至此,ART运行时的GC标记阶段就执行完毕。接下来我继续分析并行GC的Handle Dirty Object阶段。
5. HandleDirtyObjectsPhase。
MarkSweep、PartialMarkSweep和StickyMarkSweep三个类的Handle Dirty Object阶段都是以MarkSweep类的成员函数HandleDirtyObjectsPhase为入口,它的实现如下所示:
[cpp] view plaincopy
- bool MarkSweep::HandleDirtyObjectsPhase() {
- base::TimingLogger::ScopedSplit split("HandleDirtyObjectsPhase", &timings_);
- Thread* self = Thread::Current();
- Locks::mutatorlock->AssertExclusiveHeld(self);
-
- {
- WriterMutexLock mu(self, *Locks::heap_bitmaplock);
-
- // Re-mark root set.
- ReMarkRoots();
-
- // Scan dirty objects, this is only required if we are not doing concurrent GC.
- RecursiveMarkDirtyObjects(true, accounting::CardTable::kCardDirty);
- }
-
- ProcessReferences(self);
-
- ......
-
- // Disallow new system weaks to prevent a race which occurs when someone adds a new system
- // weak before we sweep them. Since this new system weak may not be marked, the GC may
- // incorrectly sweep it. This also fixes a race where interning may attempt to return a strong
- // reference to a string that is about to be swept.
- Runtime::Current()->DisallowNewSystemWeaks();
- return true;
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数HandleDirtyObjectsPhase主要执行以下操作:
A. 调用成员函数ReMarkRoots重新标记根集对象。
B. 调用成员函数RecursiveMarkDirtyObjects递归标记值等于Card Table中值等于DIRTY的Card。注意,此时值等于(DIRTY - 1)的Card已经在标记阶段处理过了,因此这里不需要再对它们进行处理。
C. 调用成员函数ProcessReferences处理Soft Reference、Weak Reference、Phantom Reference和Finalizer Reference等引用对象。
D. 调用Runtime类的成员函数DisallowNewSystemWeaks禁止在系统内部分配全局弱引用对象、Monitor对象和常量字符池对象等,因此这些新分配的对象会得不到标记,从而会导致在接下来的清除阶段中被回收,但是它们又是正在使用的。
在上述四个操作中,最重要的是前三个操作。对于第二个操作调用到的MarkSweep类的成员函数RecursiveMarkDirtyObjects,我们前面已经分析过了。对于第三个操作,可以参考前面Dalvik虚拟机垃圾收集(GC)过程分析一文分析的Dalvik虚拟机GC过程对引用对象的处理,ART运行时和Dalvik虚拟机对引用对象的处理逻辑是一样的。
接下来,我们主要分析第一个操作,即MarkSweep类的成员函数ReMarkRoots的实现,如下所示:
[cpp] view plaincopy
- void MarkSweep::ReMarkRoots() {
- timings_.StartSplit("ReMarkRoots");
- Runtime::Current()->VisitRoots(ReMarkObjectVisitor, this, true, true);
- timings_.EndSplit();
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数ReMarkRoots主要就是调用了我们前面分析过的Runtime类的成员函数VisitRoots来标记所有的根集对象,以便可以对它们直接和间接引用的对象进行递归标记。
理解了GC的Marking阶段之后,再学习GC的Handle Dirty Objects阶段就容易多了。接下来我们继续分析GC的Reclaim阶段。
6. ReclaimPhase
MarkSweep、PartialMarkSweep和StickyMarkSweep三个类的Reclaim阶段都是以MarkSweep类的成员函数ReclaimPhase为入口,它的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::ReclaimPhase() {
- base::TimingLogger::ScopedSplit split("ReclaimPhase", &timings_);
- Thread* self = Thread::Current();
-
- if (!IsConcurrent()) {
- ProcessReferences(self);
- }
-
- {
- WriterMutexLock mu(self, *Locks::heap_bitmaplock);
- SweepSystemWeaks();
- }
-
- if (IsConcurrent()) {
- Runtime::Current()->AllowNewSystemWeaks();
-
- base::TimingLogger::ScopedSplit split("UnMarkAllocStack", &timings_);
- WriterMutexLock mu(self, *Locks::heap_bitmaplock);
- accounting::ObjectStack* allocation_stack = GetHeap()->allocationstack.get();
- // The allocation stack contains things allocated since the start of the GC. These may have been
- // marked during this GC meaning they won't be eligible for reclaiming in the next sticky GC.
- // Remove these objects from the mark bitmaps so that they will be eligible for sticky
- // collection.
- // There is a race here which is safely handled. Another thread such as the hprof could
- // have flushed the alloc stack after we resumed the threads. This is safe however, since
- // reseting the allocation stack zeros it out with madvise. This means that we will either
- // read NULLs or attempt to unmark a newly allocated object which will not be marked in the
- // first place.
- mirror::Object** end = allocation_stack->End();
- for (mirror::Object** it = allocation_stack->Begin(); it != end; ++it) {
- const Object obj = it;
- if (obj != NULL) {
- UnMarkObjectNonNull(obj);
- }
- }
- }
-
- ......
-
- {
- WriterMutexLock mu(self, *Locks::heap_bitmaplock);
-
- // Reclaim unmarked objects.
- Sweep(false);
-
- // Swap the live and mark bitmaps for each space which we modified space. This is an
- // optimization that enables us to not clear live bits inside of the sweep. Only swaps unbound
- // bitmaps.
- timings_.StartSplit("SwapBitmaps");
- SwapBitmaps();
- timings_.EndSplit();
-
- // Unbind the live and mark bitmaps.
- UnBindBitmaps();
- }
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数ReclaimPhase首先判断当前执行的GC是并行还是非并行的。对于并行GC,在前面的Handle Dirty Object阶段,已经对引用对象作过处理了。但是对于非并行GC,由于不需要执行Handle Dirty Object阶段,因此这时就要调用MarkSweep类的成员函数ProcessReferences对Soft Reference、Weak Reference、Phantom Reference和Finalizer Reference等引用对象进行处理。
MarkSweep类的成员函数ReclaimPhase接下来再调用另外一个成员函数SweepSystemWeaks清理那些没有被标记的常量字符串、Monitor对象和在JNI创建的全局弱引用对象,它的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::SweepSystemWeaks() {
- Runtime* runtime = Runtime::Current();
- timings_.StartSplit("SweepSystemWeaks");
- runtime->GetInternTable()->SweepInternTableWeaks(IsMarkedCallback, this);
- runtime->GetMonitorList()->SweepMonitorList(IsMarkedCallback, this);
- SweepJniWeakGlobals(IsMarkedCallback, this);
- timings_.EndSplit();
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
回到MarkSweep类的成员函数ReclaimPhase中,接下来是针对并行GC进行处理。在前面的Handle Dirty Object阶段,并行GC禁止了创建常量字符串、Monitor对象和JNI全局弱引用对象。现在由于对这三类对象已经处理完毕,因此就可以调用Runtime类的成员函数AllowNewSystemWeaks恢复可以创建了。
对于并行GC,还需要做的一个操作是,将Allocation Stack的对象对应的Mark Bitmap标记位清零。在并行GC的Marking阶段,我们已经将Allocation Stack与Live Stack进行了交换,因此这时候保存在Allocation Stack的对象都是在并行GC执行的过程中分配的。这部分对象在并行GC执行的过程中,有可能会被标记。这意味着接下来交换Mark Bitmap和Live Bitmap时,这些保存在Allocation Stack的对象对应的Live Bitmap位是被设置为1的。这样会导致下次执行Sticky Mark Sweep时,那些既在Allocation Stack中,但又不是根集对象也不是Dirty Card可达的对象不会被回收。因此,这里就需要调用成员函数UnMarkObjectNonNull将它们在Mark Bitmap中的标记位设置为0。
再接下来,MarkSweep类的成员函数ReclaimPhase就开始调用成员函数Sweep回收那些没有被标记的对象,它的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::Sweep(bool swap_bitmaps) {
- DCHECK(markstack->IsEmpty());
- base::TimingLogger::ScopedSplit("Sweep", &timings_);
-
- const bool partial = (GetGcType() == kGcTypePartial);
- SweepCallbackContext scc;
- scc.mark_sweep = this;
- scc.self = Thread::Current();
- for (const auto& space : GetHeap()->GetContinuousSpaces()) {
- // We always sweep always collect spaces.
- bool sweep_space = (space->GetGcRetentionPolicy() == space::kGcRetentionPolicyAlwaysCollect);
- if (!partial && !sweep_space) {
- // We sweep full collect spaces when the GC isn't a partial GC (ie its full).
- sweep_space = (space->GetGcRetentionPolicy() == space::kGcRetentionPolicyFullCollect);
- }
- if (sweep_space) {
- uintptr_t begin = reinterpret_cast(space->Begin());
- uintptr_t end = reinterpret_cast(space->End());
- scc.space = space->AsDlMallocSpace();
- accounting::SpaceBitmap* live_bitmap = space->GetLiveBitmap();
- accounting::SpaceBitmap* mark_bitmap = space->GetMarkBitmap();
- if (swap_bitmaps) {
- std::swap(live_bitmap, mark_bitmap);
- }
- if (!space->IsZygoteSpace()) {
- base::TimingLogger::ScopedSplit split("SweepAllocSpace", &timings_);
- // Bitmaps are pre-swapped for optimization which enables sweeping with the heap unlocked.
- accounting::SpaceBitmap::SweepWalk(live_bitmap, mark_bitmap, begin, end,
- &SweepCallback, reinterpret_cast<void*>(&scc));
- } else {
- base::TimingLogger::ScopedSplit split("SweepZygote", &timings_);
- // Zygote sweep takes care of dirtying cards and clearing live bits, does not free actual
- // memory.
- accounting::SpaceBitmap::SweepWalk(live_bitmap, mark_bitmap, begin, end,
- &ZygoteSweepCallback, reinterpret_cast<void*>(&scc));
- }
- }
- }
-
- SweepLargeObjects(swap_bitmaps);
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
参数swap_bitmaps表示在回收各个Space的垃圾时,是否需要交换它们的Mark Bitmap和Live Bitmap,这里传进来的值等于false,表示不需要交换。交换的好处是可以在不锁住堆的情况下执行垃圾回收阶段。从前面分析的GarbageCollector类的成员函数Run可以知道,目 前ART运行堆的垃圾回收阶段是在锁住堆的前提下执行的,因此这里就不需要将参数swap_bitmaps设置为true。
MarkSweep类的成员函数Sweep首先回收Contiouous Space的垃圾,再回收Discontinous Space的垃圾,也就是Large Object Space的垃圾。这里首先要注意的一点是,只有Mark Sweep和Partial Mark Sweep会调用MarkSweep类的成员函数Sweep来清除垃圾,Sticky Mark Sweep会重写父类Mark Sweep的成员函数Sweep,因为它需要清理的只是Allocation Stack的垃圾。因此,我们下面的讨论都是Mark Sweep和Partial Mark Sweep的垃圾清理过程。
无论是Mark Sweep还是Partial Mark Sweep,回收策略为kGcRetentionPolicyAlwaysCollect的Space的垃圾都是需要回收的。但是对于Mark Sweep,回收策略为kGcRetentionPolicyFullCollect的Space的垃圾也是需要回收的。对于每一个Continous Space,如果通过上述逻辑判断出它的垃圾是需要回收的,即变量sweep_space的值等于true,那么就需要调用SpaceBitmap类的成员函数SweepWalk进行回收。
我们知道,Image Space、Zygote Space和Allocation Space都是Continuous Space,它们的回收策略分别为kGcRetentionPolicyNeverCollect、kGcRetentionPolicyAlwaysCollect和kGcRetentionPolicyFullCollect,因此,这里需要进行垃圾回收的只有Zygote Space和Allocation Space。但是由于Zygote Space是用来在Zygote进程及其子进程共享的,因此,这里又不能对它进行真正的回收,否则的话,就会需要对这部内存进行写操作,从而导致这部分内存不能够再共享。这一点与前面Dalvik虚拟机垃圾收集(GC)过程分析一文分析的Dalvik虚拟机垃圾收集过程对Zygote堆的处理是一样的。
因此,在调用SpaceBitmap类的成员函数SweepWalk对Zygote Space和Allocation Space的垃圾进行回收时,设置的回调函数是不一样的。对于Allocation Space,设置的回调函数为MarkSweep类的静态成员函数SweepCallback;而对于Zygote Space,设置的回调函数为MarkSweep类的静态成员函数ZygoteSweepCallback。SpaceBitmap类的成员函数SweepWalk所做的事情就是找出那些上次GC之后是存活的,即在Live Bitmap中的标记位等于1,但是在当前GC时,在Mark Bitmap的标记位等于0,即没有被标记的对象,然后再调用传递给它的回调函数对上述找到的对象进行真正清理操作。这一点与前面Dalvik虚拟机垃圾收集(GC)过程分析一文分析的Dalvik虚拟机垃圾清理逻辑也是一样的。接下来我们就分别看看MarkSweep类的静态成员函数SweepCallback和ZygoteSweepCallback的实现。
MarkSweep类的静态成员函数SweepCallback的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::SweepCallback(size_t num_ptrs, Object* ptrs, void arg) {
- SweepCallbackContext context = static_cast<SweepCallbackContext>(arg);
- MarkSweep* mark_sweep = context->mark_sweep;
- Heap* heap = mark_sweep->GetHeap();
- space::AllocSpace* space = context->space;
- Thread* self = context->self;
- Locks::heap_bitmaplock->AssertExclusiveHeld(self);
- // Use a bulk free, that merges consecutive objects before freeing or free per object?
- // Documentation suggests better free performance with merging, but this may be at the expensive
- // of allocation.
- size_t freed_objects = num_ptrs;
- // AllocSpace::FreeList clears the value in ptrs, so perform after clearing the live bit
- size_t freed_bytes = space->FreeList(self, num_ptrs, ptrs);
- heap->RecordFree(freed_objects, freed_bytes);
- mark_sweep->freedobjects.fetch_add(freed_objects);
- mark_sweep->freedbytes.fetch_add(freed_bytes);
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
参数ptrs指向一组需要回收的对象占用的内存块的地址,而参数num_ptrs则表示这组内存块的个数。第三个参数arg指向一个SweepCallbackContext对象,这个对象的成员变量space描述了参数ptrs指向的内存块是所属的Space。有了这些信息之后,就可以调用相应的Space的成员函数FreeList进行真正的垃圾回收了。我们知道,Allocation Space是使用DlMallocSpace来描述的,因此,这里就是调用DlMallocSpace类的成员函数FreeList来回收内存。
从前面ART运行时为新创建对象分配内存的过程分析一文可以知道,DlMallocSpace类是通过C库提供的内存管理接口malloc来分配内存的,因此,它在回收内存时,也是使用对应的C库内存管理接口free来回收内存。这一点与Dalvik虚拟机垃圾收集(GC)过程分析一文分析的Dalvik虚拟机的垃圾回收逻辑也是一样的。
MarkSweep类的静态成员函数SweepCallback最后还调用了Heap类的成员函数Record记录了当前释放的对象个数和内存字节数,以及更新Mark Sweep内部的释放对象个数和内存字节数。
MarkSweep类的静态成员函数ZygoteSweepCallback的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::ZygoteSweepCallback(size_t num_ptrs, Object* ptrs, void arg) {
- SweepCallbackContext context = static_cast<SweepCallbackContext>(arg);
- Locks::heap_bitmaplock->AssertExclusiveHeld(context->self);
- Heap* heap = context->mark_sweep->GetHeap();
- // We don't free any actual memory to avoid dirtying the shared zygote pages.
- for (size_t i = 0; i < num_ptrs; ++i) {
- Object obj = static_cast<Object>(ptrs[i]);
- heap->GetLiveBitmap()->Clear(obj);
- heap->GetCardTable()->MarkCard(obj);
- }
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
由于Zygote Space并不需要执行真正的垃圾清理工作,因此,MarkSweep类的静态成员函数只是相应清理了垃圾对象在其Live Bitmap的标记位,以及将它在Card Table中对应的Card设置为DIRTY,使得下次GC时它们引用的其它对象也不会被回收。
MarkSweep类的成员函数Sweep中,回收完成Continous Space的垃圾之后,接下来再调用成员函数SweepLargeObjects回收Large Object Space的垃圾,它的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::SweepLargeObjects(bool swap_bitmaps) {
- base::TimingLogger::ScopedSplit("SweepLargeObjects", &timings_);
- // Sweep large objects
- space::LargeObjectSpace* large_object_space = GetHeap()->GetLargeObjectsSpace();
- accounting::SpaceSetMap* large_live_objects = large_object_space->GetLiveObjects();
- accounting::SpaceSetMap* large_mark_objects = large_object_space->GetMarkObjects();
- if (swap_bitmaps) {
- std::swap(large_live_objects, large_mark_objects);
- }
- // O(n*log(n)) but hopefully there are not too many large objects.
- size_t freed_objects = 0;
- size_t freed_bytes = 0;
- Thread* self = Thread::Current();
- for (const Object* obj : large_live_objects->GetObjects()) {
- if (!large_mark_objects->Test(obj)) {
- freed_bytes += large_object_space->Free(self, const_cast<Object*>(obj));
- ++freed_objects;
- }
- }
- freed_largeobjects.fetch_add(freed_objects);
- freed_large_objectbytes.fetch_add(freed_bytes);
- GetHeap()->RecordFree(freed_objects, freed_bytes);
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
参数swap_bitmaps同样是表示是否需要交换Large Object Space的Live Bitmap和Mark Bitmap,这里传递来的值等于false,表示不需要交换。
MarkSweep类的成员函数SweepLargeObjects通过遍历Large Object Space的每一个对象,并且检查它们在Mark Bitmap的标记位是否被设置了。如果没有被设置,那么就调用Large Object Space的成员函数Free对其占用的内存块进行释放。垃圾清理完毕,MarkSweep类的成员函数SweepLargeObjects也会更新当前释放的对象计数以及内存计数。
从前面ART运行时为新创建对象分配内存的过程分析一文可以知道,ART运行时使用的Large Object Space是一个LargeObjectMapSpace,它通过映射匿名共享内存为新创建对象分配内存,因此,LargeObjectMapSpace类的成员函数Free来释放内存时,就相应地删除对应的匿名共享内存就行了,如下所示:
[cpp] view plaincopy
- size_t LargeObjectMapSpace::Free(Thread self, mirror::Object ptr) {
- MutexLock mu(self, lock_);
- MemMaps::iterator found = memmaps.find(ptr);
- CHECK(found != memmaps.end()) << "Attempted to free large object which was not live";
- DCHECK_GE(num_bytesallocated, found->second->Size());
- size_t allocation_size = found->second->Size();
- num_bytesallocated -= allocation_size;
- --num_objectsallocated;
- delete found->second;
- memmaps.erase(found);
- return allocation_size;
- }
这个函数定义在文件art/runtime/gc/space/large_object_space.cc中。
LargeObjectMapSpace类之前分配的内存都是使用一个MemMap对象来描述,并且保存在成员变量mem_maps_描述的一个Map中,因此,LargeObjectMapSpace类的成员函数Free就先在这个Map里面找到与参数ptr对应的MemMap,然后将其从Map中移除。从Map中移除之后,对应的MemMap对象就会被析构,而MemMap对象被析构的时候,它内部维护的匿名共享内存就会被删除了,如下所示:
[cpp] view plaincopy
- MemMap::~MemMap() {
- if (basebegin == NULL && basesize == 0) {
- return;
- }
- int result = munmap(basebegin, basesize);
- if (result == -1) {
- PLOG(FATAL) << "munmap failed";
- }
- }
这个函数定义在文件art/runtime/mem_map.cc中。
从这里就可以看到,MemMap对象内部使用的匿名共享内存通过系统接口munmap进行删除。
这样,我们就分析完成各个Space的垃圾回收过程了,回到MarkSweep类的成员函数ReclaimPhase中,它最后还要做两件事情。第一件事情是调用MarkSweep类的成员函数SwapBitmaps交换Live Bitmap和Mark Bitmap,使得Live Bitmap始终记录的是上次GC之后存活的对象。第二件事情是调用MarkSweep类的成员函数UnBindBitmaps将Mark Bitmap清空,以便下次GC时可以使用。
至此,我们就分析完成Mark Sweep和Partial Mark Sweep的Reclaim阶段了。前面提到,Sticky Mark Sweep重写了父类MarkSweep的成员函数Sweep,以便可以只回收Allocation Stack的垃圾,它的实现如下所示:
[cpp] view plaincopy
- void StickyMarkSweep::Sweep(bool swap_bitmaps) {
- accounting::ObjectStack* live_stack = GetHeap()->GetLiveStack();
- SweepArray(live_stack, false);
- }
这个函数定义在文件art/runtime/gc/collector/sticky_mark_sweep.cc中。
注意,这里虽然获得的是ART运行时的Live Stack,但是因为在前面的Marking阶段中,Live Stack和Allocation Stack已经交换过了,因此这里获得的实际上Allocation Stack。有了这个Allocation Stack之后,接下来就调用从父类MarkSweep继承下来的成员函数SweepArray来处理它里面的垃圾对象。
MarkSweep类的成员函数SweepArray的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::SweepArray(accounting::ObjectStack* allocations, bool swap_bitmaps) {
- space::DlMallocSpace* space = heap_->GetAllocSpace();
- timings_.StartSplit("SweepArray");
- // Newly allocated objects MUST be in the alloc space and those are the only objects which we are
- // going to free.
- accounting::SpaceBitmap* live_bitmap = space->GetLiveBitmap();
- accounting::SpaceBitmap* mark_bitmap = space->GetMarkBitmap();
- space::LargeObjectSpace* large_object_space = GetHeap()->GetLargeObjectsSpace();
- accounting::SpaceSetMap* large_live_objects = large_object_space->GetLiveObjects();
- accounting::SpaceSetMap* large_mark_objects = large_object_space->GetMarkObjects();
- if (swap_bitmaps) {
- std::swap(live_bitmap, mark_bitmap);
- std::swap(large_live_objects, large_mark_objects);
- }
-
- size_t freed_bytes = 0;
- size_t freed_large_object_bytes = 0;
- size_t freed_objects = 0;
- size_t freed_large_objects = 0;
- size_t count = allocations->Size();
- Object objects = const_cast<Object>(allocations->Begin());
- Object** out = objects;
- Object** objects_to_chunk_free = out;
-
- // Empty the allocation stack.
- Thread* self = Thread::Current();
- for (size_t i = 0; i < count; ++i) {
- Object* obj = objects[i];
- // There should only be objects in the AllocSpace/LargeObjectSpace in the allocation stack.
- if (LIKELY(mark_bitmap->HasAddress(obj))) {
- if (!mark_bitmap->Test(obj)) {
- // Don't bother un-marking since we clear the mark bitmap anyways.
- *(out++) = obj;
- // Free objects in chunks.
- ......
- if (static_cast(out - objects_to_chunk_free) == kSweepArrayChunkFreeSize) {
- timings_.StartSplit("FreeList");
- size_t chunk_freed_objects = out - objects_to_chunk_free;
- freed_objects += chunk_freed_objects;
- freed_bytes += space->FreeList(self, chunk_freed_objects, objects_to_chunk_free);
- objects_to_chunk_free = out;
- timings_.EndSplit();
- }
- }
- } else if (!large_mark_objects->Test(obj)) {
- ++freed_large_objects;
- freed_large_object_bytes += large_object_space->Free(self, obj);
- }
- }
- // Free the remaining objects in chunks.
- ......
- if (out - objects_to_chunk_free > 0) {
- timings_.StartSplit("FreeList");
- size_t chunk_freed_objects = out - objects_to_chunk_free;
- freed_objects += chunk_freed_objects;
- freed_bytes += space->FreeList(self, chunk_freed_objects, objects_to_chunk_free);
- timings_.EndSplit();
- }
- ......
- timings_.EndSplit();
-
- timings_.StartSplit("RecordFree");
- ......
- freedobjects.fetch_add(freed_objects);
- freed_largeobjects.fetch_add(freed_large_objects);
- freedbytes.fetch_add(freed_bytes);
- freed_large_objectbytes.fetch_add(freed_large_object_bytes);
- timings_.EndSplit();
-
- timings_.StartSplit("ResetStack");
- allocations->Reset();
- timings_.EndSplit();
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
保存在Allocation Stack中的对象要么是在Allocation Space上分配的,要么是Large Object Space分配的,因此MarkSweep类的成员函数SweepArray一开始就先取出这两个Space的Mark Bitmap,然后再遍历Allocation Stack的对象。对于Allocation Stack中每一个对象,首先判断它在Allocation Space的Mark Bitmap中的标记位是否被设置了。如果没有设置了,那么就说明这是一个需要回收的对象。如果在Allocation Space的Mark Bitmap中的标记位没有被设置,再判断它在Large Object Space的Mark Bitmap中的标记位是否被设置了。如果没有被设置,那么也说明这是一个需要回收的对象。
对于属于Allocation Space的垃圾对象,MarkSweep类的成员函数SweepArray通过调用DlMallocSpace类的成员函烽FreeList来批量回收,而对于属于Large Object Space的垃圾对象,MarkSweep类的成员函数SweepArray则是通过LargeObjectMapSpace类的成员函数Free来逐个回收。
最后,MarkSweep类的成员函数SweepArray更新了当前释放的对象个数和内存字节数,以及清空了Allocation Stack,以便下次可以继续使用。
至此,Sticky Mark Sweep的Reclaim阶段也分析完成了。接下来还剩下最后一个GC阶段,即Finish阶段。
7. FinishPhase
MarkSweep、PartialMarkSweep和StickyMarkSweep三个类的Reclaim阶段都是以MarkSweep类的成员函数FinishPhase为入口,它的实现如下所示:
[cpp] view plaincopy
- void MarkSweep::FinishPhase() {
- base::TimingLogger::ScopedSplit split("FinishPhase", &timings_);
- // Can't enqueue references if we hold the mutator lock.
- Object* cleared_references = GetClearedReferences();
- Heap* heap = GetHeap();
- timings_.NewSplit("EnqueueClearedReferences");
- heap->EnqueueClearedReferences(&cleared_references);
-
- ......
-
- timings_.NewSplit("GrowForUtilization");
- heap->GrowForUtilization(GetGcType(), GetDurationNs());
-
- timings_.NewSplit("RequestHeapTrim");
- heap->RequestHeapTrim();
-
- // Update the cumulative statistics
- total_timens += GetDurationNs();
- total_paused_timens += std::accumulate(GetPauseTimes().begin(), GetPauseTimes().end(), 0,
- std::plus());
- total_freedobjects += GetFreedObjects() + GetFreedLargeObjects();
- total_freedbytes += GetFreedBytes() + GetFreedLargeObjectBytes();
-
- ......
-
- // Clear all of the spaces' mark bitmaps.
- for (const auto& space : GetHeap()->GetContinuousSpaces()) {
- if (space->GetGcRetentionPolicy() != space::kGcRetentionPolicyNeverCollect) {
- space->GetMarkBitmap()->Clear();
- }
- }
- markstack->Reset();
-
- // Reset the marked large objects.
- space::LargeObjectSpace* large_objects = GetHeap()->GetLargeObjectsSpace();
- large_objects->GetMarkObjects()->Clear();
- }
这个函数定义在文件art/runtime/gc/collector/mark_sweep.cc中。
MarkSweep类的成员函数FinishPhase负责执行一些善后工作,包括:
A. 调用Heap类的成员函数EnqueueClearedReferences将目标对象已经被回收了的引用对象添加到各自关联的队列中去,以便应用程序可以知道它们的目标对象已经被回收了。
B. 调用Heap类的成员函数GrowForUtilization根据预先设置的堆目标利率以及最小和最大空闲内存数增长堆的大小。
C. 调用Heap类的成员函数RequestHeapTrim对堆进行裁剪,以便可以将空闲内存临时归还给操作系统。
D. 更新GC执行时间、暂停时间、释放的对象个数和内存字节数等统计数据。
E. 清空所有Space的Mark Bitmap和ART运行时的Mark Stack。
其中,A和B两个工作和前面Dalvik虚拟机垃圾收集(GC)过程分析一文分析的Dalvik虚拟机垃圾收集的Finish阶段做的工作是一样的,因此这里不再详细分析。此外,C这个工作会是通过向前面提到的在Java层创建的Heap Trimmer Daemon线程发送一个消息来完成的。Java层的Heap Trimmer Daemon线程收到这个通知之后,就会调用Heap类的成员函数Trim来执先裁剪堆的工作,如下所示:
[cpp] view plaincopy
- size_t Heap::Trim() {
- // Handle a requested heap trim on a thread outside of the main GC thread.
- return allocspace->Trim();
- }
这个函数定义在文件art/runtime/gc/heap.cc中。
从这里就可以看到,Heap类的成员函数Trim主要是裁剪Allocation Space的内存。
由于Heap类的成员变量alloc_space_指向的是一个DlMallocSpace对象,因此,接下来就调用DlMallocSpace类的成员函数Trim来裁剪内存,它的实现如下所示:
[cpp] view plaincopy
- size_t DlMallocSpace::Trim() {
- MutexLock mu(Thread::Current(), lock_);
- // Trim to release memory at the end of the space.
- mspacetrim(mspace, 0);
- // Visit space looking for page-sized holes to advise the kernel we don't need.
- size_t reclaimed = 0;
- mspace_inspectall(mspace, DlmallocMadviseCallback, &reclaimed);
- return reclaimed;
- }
这个函数定义在文件art/runtime/gc/space/dlmalloc_space.cc中。
从这里就可以看到,与前面Dalvik虚拟机Java堆创建过程分析一文,ART运行时也是通过C库内存管理接口mspace_trim和mspace_inspect_all来裁剪内存的,因此这里就不再详细分析了。
至此,我们就分析完成GC的Finish阶段了,整个ART运行时的GC过程也分析完成了。从这个过程我们就可以看出,与前面Dalvik虚拟机垃圾收集机制简要介绍和学习计划这个系列的文章分析的Dalvik虚拟机GC相比,ART运行时GC的优势在于:
1. ART运行时堆的划分和管理更细致,它分为Image Space、Zygote Space、Allocation Space和Large Object Space四个Space,再加上一个Allocation Stack。其中,Allocation Space和Large Object Space和Dalvik虚拟机的Zygote堆和Active堆作用是一样的,而其余的Space则有特别的作用,例如,Image Space的对象是永远不需要回收的。
2. ART运行时的每一个Space都有不同的回收策略,ART运行时根据这个特性提供了Mark Sweep、Partial Mark Sweep和Sticky Mark Sweep等三种回收力度不同的垃圾收集器。其中,Mark Sweep的垃圾回收力度最大,它会同时回收Zygote Space、Allocation Space和Large Object Space的垃圾,Partial Mark Sweep的垃圾回收力度居中,它只会同时回收Allocation Space和Large Object Space的垃圾,而Sticky Mark Sweep的垃圾回收力度最小,它只会回收Allocation Stack的垃圾,即上次GC以后分配出来的又不再使用了的对象。力度越大的垃圾收集器,回收垃圾时需要的时候也就越长。这样我们就可以在应用程序运行的过程中根据不同的情景使用不同的垃圾收集器,那就可以更有效地执行垃圾回收过程。
3. ART运行时充分地利用了设备的CPU多核特性,在并行GC的执行过程中,将每一个并发阶段的工作划分成多个子任务,然后提交给一个线程池执行,这样就可以更高效率地完成整个GC过程,避免长时间对应用程序造成停顿。
虽然ART运行时的GC更有优势,但是它也实现得更加得复杂,而且很多方法也是借鉴了Dalvik虚拟机的GC机制的,因此,在学习ART运行时的GC机制之前,最好能够先研究一下Dalvik虚拟机的GC机制,具体可以参考Dalvik虚拟机垃圾收集机制简要介绍和学习计划这个系列的文章,而需要重新学习ART运行时的GC机制可以参考ART运行时垃圾收集机制简要介绍和学习计划这个系列的文章,更多的信息可以关注老罗的新浪微博:http://weibo.com/shengyangluo。