生成式AI初学者教程
第四章:提示工程基础

如何撰写 LLM 的提示很重要,精心设计的提示可以比不精心设计的提示取得更好的结果。 但这些概念到底是什么,提示、提示工程以及我如何改进我发送给 LLMs 的内容? 诸如此类的问题正是本章和下一章想要解答的。
_生成式人工智能_能够根据用户请求创建新内容(例如文本、图像、音频、代码等)。 它使用 LLMs 来实现这一目标,例如 OpenAI 的 GPT 模型系列,这些模型通过使用自然语言和代码进行训练。
用户现在可以使用熟悉的语言(如聊天)与这些模型进行交互,而无需任何技术专业知识或培训。 这些模型是基于提示的——用户发送文本输入(提示)并获取人工智能响应(完成)。 然后,他们可以在多轮对话中迭代地“与人工智能聊天”,完善他们的提示,直到响应符合他们的预期。
“提示”现在成为生成式人工智能应用程序的主要编程界面,告诉模型要做什么并影响返回响应的质量。 “提示工程”是一个快速发展的研究领域,专注于提示的“设计和优化”,以大规模提供一致且高质量的响应。
学习目标
在本章中,我们将了解什么是提示工程、为什么它很重要,以及如何针对给定的模型和应用程序目标制定更有效的提示。 我们将了解提示工程的核心概念和最佳实践,并了解交互式 Jupyter Notebooks“沙箱”环境,在 Notebooks 中我们可以看到这些概念应用于实际示例。
在本课结束时,我们将能够:
- 解释什么是提示工程及其重要性。
- 描述提示的组成部分及其使用方法。
- 学习提示工程的最佳实践和技术。
- 结合 OpenAI 将学到的技术应用于实际示例。
学习沙盒
目前,提示工程更多的是玄学而不是科学。 提高我们直觉的最佳方法是“更多练习”并采用试错方法,将应用程序领域的专业知识与推荐的技术和特定于模型的优化相结合。
本课程附带的 Jupyter Notebook 提供了一个_沙盒_环境,您可以在其中尝试所学内容 - 边学边做,或者作为最后代码挑战的一部分。 要完成练习,您需要:
-
设置 OpenAI API 密钥 - 已部署的 LLM 的服务端点。
-
Python 运行时 - 可以让 Notebook 运行。
我们使用一个带有 Python 3 运行时的开发容器来检测这个存储库。 只需在 GitHub Codespaces 或本地 Docker 桌面上打开 Repo,即可自动激活运行时。 然后打开笔记本并选择Python 3.x 内核以准备 Notebook。
默认 Notebook 设置为与 OpenAI API 密钥一起使用。 只需将文件夹根目录中的“.env.copy”文件复制到“.env”,并使用您的 API 密钥更新“OPENAI_API_KEY=”行 - 一切就完成了。
该 Notebook 附带入门练习 - 但我们鼓励您添加自己的Markdown描述)和代码(提示请求)部分来尝试更多示例或想法 - 并建立您对提示工程设计的感觉。
Our Startup 的使命
现在,让我们来谈谈这个主题与 Our Startup 的使命[将人工智能创新带入教育]有何关系(https://educationblog.microsoft.com/2023/06/collaborating-to-bring-ai-innovation-to-education) 。 我们希望构建由人工智能驱动的个性化学习应用程序 - 所以让我们考虑一下我们应用程序的针对不同用户如何“设计”提示:
- 管理员可能会要求人工智能分析课程数据以识别覆盖范围的差距_。 人工智能可以总结结果或用代码将其可视化。
- 教育者可能会要求人工智能为目标受众和主题生成教学计划。 AI可以按照指定的格式构建个性化计划。
- 学生可能会要求人工智能辅导他们学习困难的科目。 人工智能现在可以通过适合学生水平的课程、结合提示和示例来指导学生。
这只是冰山一角。 查看 教育中的提示工程 - 一个由教育专家设计的开源提示库 ! 尝试在沙箱中运行其中一些提示或使用 OpenAI Playground 看看会产生什么结果!
什么是提示工程?
在本章中,我们将提示工程定义为设计和优化文本输入(提示) 的过程,以便为指定的应用程序目标和模型提供一致且高质量的响应(完成) 。 我们可以将其视为一个两步过程:
- 设计指定模型和目标的初始提示
- 通过迭代的方式提炼提示语以提高响应质量
这必然是一个反复尝试的过程,需要用户的直觉和努力才能获得最佳结果。 那么为什么它很重要呢? 要回答这个问题,我们首先需要了解三个概念:
- Tokenization = 模型如何“看到”提示
- Base LLMs = 基础模型如何“处理”提示
- Instruction-Tuned LLM = 模型现在如何查看“任务”
Tokenization
LLM 将提示视为标记序列,其中不同的模型(或模型的版本)可以以不同的方式对同一提示进行标记。 由于 LLM 是根据标记(而不是原始文本)进行训练的,因此提示标记化的方式对生成的响应的质量有直接影响。
要直观地了解标记化的工作原理,请尝试使用如下所示的 OpenAI Tokenizer 等工具。 复制您的提示 - 并查看如何将其转换为标记,注意空白字符和标点符号的处理方式。 请注意,此例子显示的是较旧的 LLM (GPT-3) - 因此使用较新的模型尝试此操作可能会产生不同的结果。

概念: 基础模型
Once a prompt is tokenized, the primary function of the "Base LLM" (or Foundation model) is to predict the token in that sequence. Since LLMs are trained on massive text datasets, they have a good sense of the statistical relationships between tokens and can make that prediction with some confidence. Not that they don't understand the meaning of the words in the prompt or token; they just see a pattern they can "complete" with their next prediction. They can continue predicting the sequence till terminated by user intervention or some pre-established condition.
Want to see how prompt-based completion works? Enter the above prompt into the Azure OpenAI Studio Chat Playground with the default settings. The system is configured to treat prompts as requests for information - so you should see a completion that satisfies this context.
But what if the user wanted to see something specific that met some criteria or task objective? This is where instruction-tuned LLMs come into the picture.
一旦提示被标记化,“Base LLM”的主要功能 (或基础模型)是预测该序列中的标记。 由于 LLMs 接受过大量文本数据集的训练,因此他们对标记之间的统计关系有很好的理解,并且可以自信地做出预测。 并不是说他们不理解提示或标记中单词的含义,他们只是看到了一个可以通过下一个预测“完成”的模式。 他们可以继续预测序列,直到被用户干预或某些预先设定的条件终止。
想了解基于提示补全是如何工作的吗? 使用默认设置将上述提示输入到 Azure OpenAI Studio Chat Playground。 系统配置会将提示视为信息请求 - 因此您应该看到满足此上下文的补全。
但是,如果用户想要查看满足某些标准或任务目标的特定内容怎么办? 这就是通过 LLMs 进行指令调整发挥作用的地方。
概念: LLMs 中的指令调整
LLMs 中的指令调整 从基础模型开始,并使用以下参数对其进行微调 可以包含明确指令的示例或输入/输出对(例如多轮“消息”),以及人工智能尝试遵循该指令的响应。
它使用诸如人类反馈强化学习 (RLHF) 之类的技术,可以训练模型“遵循指令”并“从反馈中学习”,从而产生更适合实际应用且与用户目标更相关的响应。
让我们尝试一下 - 重新访问上面的提示,但现在更改系统消息,提供以下指令作为上下文:
Summarize content you are provided with for a second-grade student. Keep the result to one paragraph with 3-5 bullet points.
看看现在如何调整结果以反映所需的目标和格式? 教育工作者现在可以直接在该课程的 ppt 中使用此结果。

为什么我们需要提示工程
现在我们知道了 LLMs 如何处理提示,让我们谈谈为什么我们需要提示工程。 答案在于,当前的 LLMs 的算法也有许多挑战,如果不及时优化,就很难实现“可靠且一致的补全”。 例如:
-
模型响应是随机的。相同的提示可能会针对不同的模型或模型版本产生不同的响应。 甚至可能在不同时间使用相同模型产生不同的结果。 提示工程技术可以通过提供更好帮助我们最大限度地减少这些变化所带来的影响。
-
模型可以产生幻觉响应。模型是使用大型但有限数据集进行预训练的,这意味着它们缺乏有关训练范围之外的概念的知识。 因此,它们可能会产生不准确、虚构或与已知事实直接矛盾的完成结果。 提示工程技术可以帮助用户识别和减轻幻觉,例如通过向人工智能询问出处或推理过程。
-
模型功能会有所不同。 较新的模型或模型迭代将具有更丰富的功能,但也会带来独特的怪癖以及成本和复杂性方面的平衡。 提示工程可以帮助我们开发最佳实践和工作流程,以可扩展和无缝的方式消除差异并适应特定于模型的要求。
让我们看看 OpenAI 或 Azure OpenAI Playground 中的实际情况:
- 对不同的 LLM 部署(例如 OpenAI、Azure OpenAI、Hugging Face)使用相同的提示 - 您看到差异了吗?
- 对相同的 LLM 部署(例如 Azure OpenAI Playground)重复使用相同的提示 - 产生的结果有何不同?
幻觉示例
想了解幻觉是如何运作的吗? 想象一个提示,指示人工智能为不存在的主题生成内容(以确保在训练数据集中没有该信息)。 例如 - 我尝试了这个提示:
Prompt: generate a lesson plan on the Martian War of 2076.
网络搜索显示,有关于火星战争的虚构叙述(例如电视剧或书籍),但没有 2076 年的故事。常识还告诉我们,2076 年是“未来”,因此无法与真实事件联系起来。
那么,当我们对不同的 LLMs 提供者运行此提示时会发生什么?
响应 1: OpenAI Playground (GPT-35)

响应 2: Azure OpenAI Playground (GPT-35)
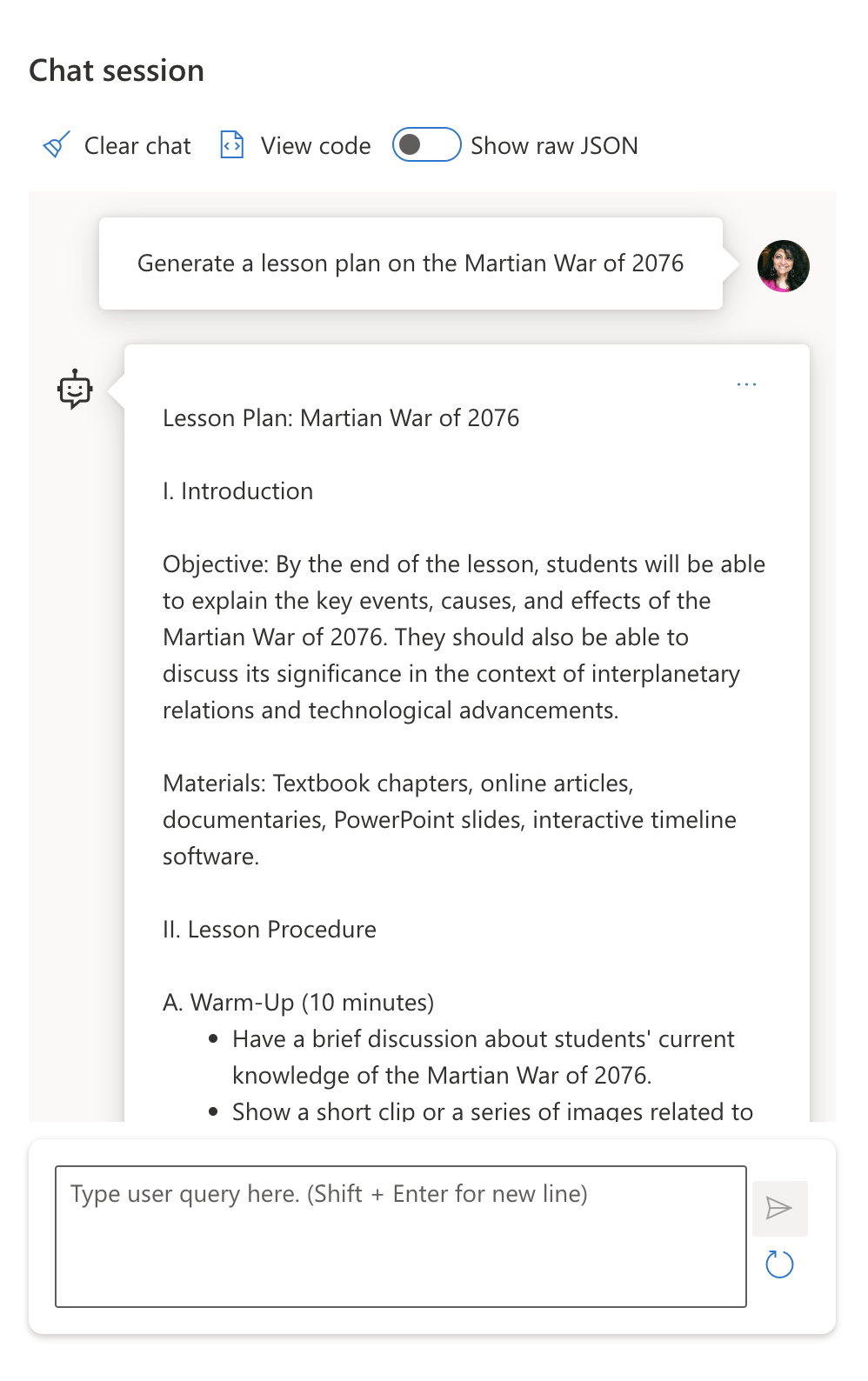
响应 3: : Hugging Face Chat Playground (LLama-2)

正如预期的那样,由于随机行为和模型能力变化,每个模型(或模型版本)都会产生略有不同的响应。 例如,一个模型针对八年级受众,而另一个模型则假设高中生。 但所有三个模型确实生成了可以让不知情的用户相信该事件是真实的响应
像元提示和温度配置这样的提示工程技术可以在一定程度上减少模型幻觉。 新的提示工程架构还将新工具和技术无缝地融入到提示流程中,以减轻或减少其中一些影响。
案例学习: GitHub Copilot
让我们通过一个案例研究来了解如何在实际解决方案中使用提示工程:GitHub Copilot。
GitHub Copilot 是您的“AI 结对编程器” - 它将文本提示转换为代码补全,并集成到您的开发环境(例如 Visual Studio Code)中,以提供无缝的用户体验。 正如下面的系列博客中所述,最早的版本基于 OpenAI Codex 模型 - 工程师很快意识到需要微调模型并开发更好的提示工程技术,以提高代码质量。 7 月,他们 首次推出了超越 Codex 模型的改进人工智能模型 以获得更快的建议。
按顺序阅读帖子,了解他们的成长过程
- 2023 年 5 月 | GitHub Copilot is Getting Better at Understanding Your Code
- 2023 年 5 月 | Inside GitHub: Working with the LLMs behind GitHub Copilot.
- 2023 年 6 月 | How to write better prompts for GitHub Copilot.
- 2023 年 7 月 | .. GitHub Copilot goes beyond Codex with improved AI model
- 2023 年 7 月 | A Developer's Guide to Prompt Engineering and LLMs
- 2023 年 9 月 | How to build an enterprise LLM app: Lessons from GitHub Copilot
您还可以浏览他们的工程师博客以获取更多帖子,例如该链接 展示了如何应用这些模型和技术来驱动现实世界的应用程序。
构建提示的方法
我们已经了解了为什么提示工程重要性 - 现在让我们了解提示是如何构建的,以便我们可以评估针对不同的技术以实现更有效的提示设计。
基础提示
让我们从基础提示开始:发送到模型的文本输入,没有其他上下文。 这是一个例子 - 当我们将美国国歌的前几个单词发送到 OpenAI Completion API 时,它会立即完成下一个单词的响应 几行,说明了基本的预测行为。
| Prompt (Input) | Completion (Output) |
|---|---|
| Oh say can you see | It sounds like you're starting the lyrics to "The Star-Spangled Banner," the national anthem of the United States. The full lyrics are ... |
复杂的提示
现在让我们为基础提示添加上下文和说明。 Chat Completion API 让我们可以将复杂的提示构建为集合 messages 包含:
- 反映用户输入和助理响应的输入/输出对。
- 系统消息设置助理行为或个性化。
该请求现在采用以下形式,其中标记化有效地从上下文和对话中捕获相关信息。 现在,更改系统上下文对补全质量的影响并与提供的用户输入一样。
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)指令式的提示
在上面的示例中,用户提示是一个简单的文本查询,可以解释为信息请求。 通过指令提示,我们可以使用该文本更详细地指定任务,从而为人工智能提供更好的指导。 这是一个例子:
| Prompt (Input) | Completion (Output) | Instruction Type |
|---|---|---|
| Write a description of the Civil War | returned a simple paragraph | Simple |
| Write a description of the Civil War. Provide key dates and events and describe their significance | returned a paragraph followed by a list of key event dates with descriptions | Complex |
| Write a description of the Civil War in 1 paragraph. Provide 3 bullet points with key dates and their significance. Provide 3 more bullet points with key historical figures and their contributions. Return the output as a JSON file | returns more extensive details in a text box, formatted as JSON that you can copy-paste to a file and validate as needed | Complex. Formatted. |
主要内容
在上面的示例中,提示仍然相当开放,允许 LLMs 决定其预训练数据集的哪一部分是相关的。 使用主要内容设计模式,输入文本分为两部分:
- 指令(动作)
- 相关内容(影响响应)
下面是一个示例,其中的指令是“用 2 句话总结这一点”。
| Prompt (Input) | Completion (Output) |
|:---|:---|
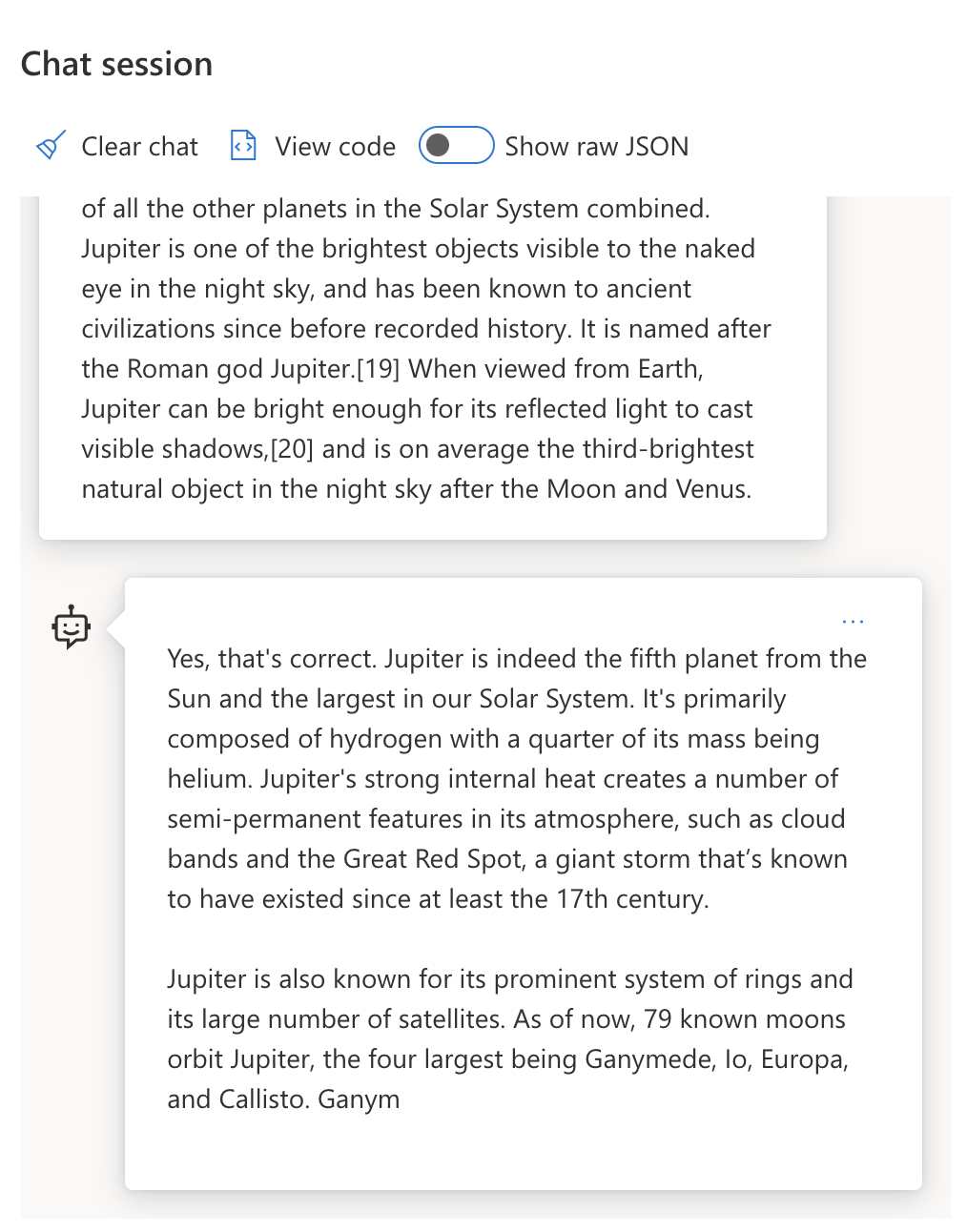
| Jupiter is the fifth planet from the Sun and the largest in the Solar System. It is a gas giant with a mass one-thousandth that of the Sun, but two-and-a-half times that of all the other planets in the Solar System combined. Jupiter is one of the brightest objects visible to the naked eye in the night sky, and has been known to ancient civilizations since before recorded history. It is named after the Roman god Jupiter.[19] When viewed from Earth, Jupiter can be bright enough for its reflected light to cast visible shadows,[20] and is on average the third-brightest natural object in the night sky after the Moon and Venus. <br/> **Summarize this in 2 short sentences** | Jupiter, the fifth planet from the Sun, is the largest in the Solar System and is known for being one of the brightest objects in the night sky. Named after the Roman god Jupiter, it's a gas giant whose mass is two-and-a-half times that of all other planets in the Solar System combined. |主要内容片段可以通过多种方式使用来驱动更有效的指令:
- 示例 - 不要用明确的指令告诉模型要做什么,而是给它提供要做什么的示例,并让它进行推断。
- 暗示 - 遵循带有“暗示”的说明,引导完成,引导模型做出更相关的响应。
- 模板 - 这些是带有占位符(变量)提示的可重复“配方”,可以使用特定用例的数据进行自定义。
用例方式
这种方法中,您使用主要内容来“向模型提供”给定指令所需输出的一些示例,并让它推断所需输出的模式。 根据提供的示例数量,我们可以有零样本提示、单样本提示、少样本提示等。
提示现在由三个部分组成:
-
任务描述
-
所需输出的一些示例
-
新示例的开始(成为隐式任务描述)
| Learning Type | Prompt (Input) | Completion (Output) | |:---|:---|:---| | Zero-shot | "The Sun is Shining". Translate to Spanish | "El Sol está brillando".| | One-shot | "The Sun is Shining" => ""El Sol está brillando". <br> "It's a Cold and Windy Day" => | "Es un día frío y ventoso". | | Few-shot | The player ran the bases => Baseball <br/> The player hit an ace => Tennis <br/> The player hit a six => Cricket <br/> The player made a slam-dunk => | Basketball | | | | |
请注意,我们如何必须在零样本提示中提供明确的指令(“翻译为西班牙语”),但它是在一次提示示例中推断出来的。 这个少样本示例展示了如何添加更多示例来让模型在不添加指令的情况下做出更准确的推理。
暗示提示
使用主要内容的另一种技术是提供暗示而不是示例。 在这种情况下,我们通过使用反映所需响应格式的片段启动来让模型朝正确的方向进行推理。 然后,模型“接受提示”,继续按照这种思路进行。
| Number of Cues | Prompt (Input) | Completion (Output) |
|:---|:---|:---|
| 0 | Jupiter is the fifth planet from the Sun and the largest in the Solar System. It is a gas giant with a mass one-thousandth that of the Sun, but two-and-a-half times that of all the other planets in the Solar System combined. Jupiter is one of the brightest objects visible to the naked eye in the night sky, and has been known to ancient civilizations since before recorded history. <br/>**Summarize This** | Jupiter is the largest planet in our Solar System and the fifth one from the Sun. It is a gas giant with a mass 1/1000th of the Sun's, but it is heavier than all the other planets combined. Ancient civilizations have known about Jupiter for a long time, and it is easily visible in the night sky..|
| 1 | Jupiter is the fifth planet from the Sun and the largest in the Solar System. It is a gas giant with a mass one-thousandth that of the Sun, but two-and-a-half times that of all the other planets in the Solar System combined. Jupiter is one of the brightest objects visible to the naked eye in the night sky, and has been known to ancient civilizations since before recorded history. <br/>**Summarize This** <br/> What we learned is that Jupiter | is the fifth planet from the Sun and the largest in the Solar System. It is a gas giant with a mass one-thousandth that of the Sun, but two-and-a-half times that of all the other planets combined. It is easily visible to the naked eye and has been known since ancient times. |
| 2 | Jupiter is the fifth planet from the Sun and the largest in the Solar System. It is a gas giant with a mass one-thousandth that of the Sun, but two-and-a-half times that of all the other planets in the Solar System combined. Jupiter is one of the brightest objects visible to the naked eye in the night sky, and has been known to ancient civilizations since before recorded history. <br/>**Summarize This** <br/> Top 3 Facts We Learned: | 1. Jupiter is the fifth planet from the Sun and the largest in the Solar System. <br/> 2. It is a gas giant with a mass one-thousandth that of the Sun...<br/> 3. Jupiter has been visible to the naked eye since ancient times ... |
| | | |提示模版
提示模板是预定义的提示配方,可以根据需要进行存储和重用,以大规模推动更一致的用户体验。 最简单的形式是,它只是一组提示示例的集合,例如 OpenAI 中的这个例子,它提供了交互式提示组件(用户和系统消息)和 AP驱动请求格式来支持重用。
在它更复杂的形式中,比如LangChain的这个例子,它包含占位符,可以替换为来自各种来源的数据(用户 输入、系统上下文、外部数据源等)来动态生成提示。 这使我们能够创建一个可重用的提示库,可用于大规模地以编程方式驱动一致的用户体验。
最后,模板的真正价值在于能够为垂直应用程序领域创建和发布提示库 - 其中提示模板现在已优化以反映特定于应用程序的上下文或示例,使响应对于目标用户受众更加相关和准确 。 Prompts For Edu repo 是这种方法的一个很好的例子,它为教育领域策划了一个提示库,重点关注课程计划等关键目标, 课程设计、学生辅导等
支持内容
如果我们将提示构建视为具有指令(任务) 和目标(主要内容),那么次要内容_像我们提供的附加上下文以某种方式影响输出。 它可以是调整参数、格式化指令、主题分类法等,可以帮助模型定制其响应以适应所需的用户目标或期望。
例如:给定一个包含课程表中所有可用课程的广泛元数据(名称、描述、级别、元数据标签、讲师等)的课程目录:
- 我们可以定义一条指令来“总结 2023 年秋季课程目录”
- 我们可以使用主要内容来提供所需输出的一些示例
- 我们可以使用次要内容来识别最感兴趣的 5 个“标签”。
现在,该模型可以按照几个示例所示的格式提供摘要 - 但如果结果具有多个标签,它可以优先考虑辅助内容中标识的 5 个标签。
提示最佳实践
现在我们知道了如何构建提示,我们可以开始思考如何设计它们以反映最佳实践。 我们可以从两部分来思考这个问题——拥有正确的心态和采用正确的技术。
提示工程思维
提示工程是一个反复试验的过程,因此请记住三个广泛的指导因素:
-
领域理解很重要。 响应准确性和相关性是应用程序或用户操作的与特定领域相关的函数。 运用您的直觉和领域专业知识进一步定制技术。 例如,在系统提示中定义特定于某个领域的个性化,或在用户提示中使用特定于某领域的模板。 提供反映特定领域上下文的辅助内容,或使用特定领域的提示和示例来指导模型走向熟悉的使用模式。
-
模型理解很重要。 我们知道模型产生的结果本质上是随机的。 但模型实现也可能因它们使用的训练数据集(预先训练的知识)、它们提供的功能(例如,通过 API 或 SDK)以及它们优化的内容类型(例如,代码与图像与文本)。 了解您正在使用的模型的优点和局限性,并利用这些知识来确定任务的优先级或构建针对模型功能进行优化的自定义模板。
-
迭代和验证很重要。 模型正在迅速发展,提示工程技术也在迅速发展。 作为领域专家,您可能有其他特定应用程序的背景或标准,这些背景或标准可能不适用于更广泛的社区。 使用提示工程工具和技术“快速启动”提示构建,然后使用您自己的直觉和领域专业知识迭代和验证结果。 记录您的见解并创建一个知识库(例如提示库),其他人可以将其用作新的基线,以便将来更快地迭代。
最佳实践
Now let's look at common best practices that are recommended by Open AI and Azure OpenAI practitioners.
现在让我们看看从业者推荐的常见最佳实践文档,包括 Open AI 和 Azure OpenAI
| What | Why |
|:---|:---|
| Evaluate the latest models. | New model generations are likely to have improved features and quality - but may also incur higher costs. Evaluate them for impact, then make migration decisions. |
| Separate instructions & context | Check if your model/provider defines _delimiters_ to distinguish instructions, primary and secondary content more clearly. This can help models assign weights more accurately to tokens. |
|Be specific and clear | Give more details about the desired context, outcome, length, format, style etc. This will improve both the quality and consistency of responses. Capture recipes in reusable templates. |
|Be descriptive, use examples |Models may respond better to a "show and tell" approach. Start with a `zero-shot` approach where you give it an instruction (but no examples) then try `few-shot` as a refinement, providing a few examples of the desired output. Use analogies.|
| Use cues to jumpstart completions | Nudge it towards a desired outcome by giving it some leading words or phrases that it can use as a starting point for the response.|
|Double Down | Sometimes you may need to repeat yourself to the model. Give instructions before and after your primary content, use an instruction and a cue, etc. Iterate & validate to see what works.|
| Order Matters | The order in which you present information to the model may impact the output, even in the learning examples, thanks to recency bias. Try different options to see what works best.|
|Give the model an “out” | Give the model a _fallback_ completion response it can provide if it cannot complete the task for any reason. This can reduce chances of models generating false or fabricated responses. |
| | |任何最佳实践一样,请记住,_您的结果可能会因模型、任务和领域而异。 使用这些作为起点,并迭代以找到最适合您的方法。 随着新模型和工具的出现,不断重新评估您的提示工程,重点关注该提示工程的可扩展性和响应质量。
作业
恭喜! 您已经完成本章的学习! 是时候用真实的例子来测试其中掌握的一些概念和技术了!
对于我们的作业,我们将使用 Jupyter Notebook 通过交互式方式完成的练习。 您还可以使用自己的 Markdown 和代码 cell 来扩展 Notebook,以自行探索性想法。
首先,fork the repo,然后
-(推荐)启动 GitHub Codespaces
- (或者)将 repo 克隆到本地设备并将其与 Docker Desktop 一起使用
- (或者)使用您的笔记本运行时环境来打开笔记本。
接下来,配置你的环境变量
- 将存储库根目录中的“.env.copy”文件复制为“.env”并填写“OPENAI_API_KEY”值。 您可以在 OpenAI Dashboard 中找到您的 API 密钥。
接下来,打开 Jupyter Notebook
- 选择运行时内核。 如果使用选项 1 或 2,只需选择开发容器提供的默认 Python 3.10.x 内核即可。
您已准备好进行操作。 请注意,这里没有正确和错误的答案 - 只是通过反复试验来探索选项,并建立对指定模型和应用程序领域有效的直觉。
因此,本章中没有代码解决方案部分。 相反,笔记本将带有标题为“My Solution:”的 Markdown 单元格,其中显示一个示例输出以供参考。
知识检查
以下哪项是遵循一些合理的最佳实践的最佳提示?
- Show me an image of red car
- Show me an image of red car of make Volvo and model XC90 parked by a cliff with the sun setting
- Show me an image of red car of make Volvo and model XC90
答:2,这是最好的提示,因为它提供了有关“内容”的详细信息并详细说明(不仅仅是任何汽车,而是特定的品牌和型号),并且还描述了整体设置。 3 是次佳的,因为它也包含很多描述。
🚀 知识拓展
看看您是否可以根据提示利用“暗示”技术:完成句子“向我显示沃尔沃制造的红色汽车的图像”。 它会做出什么反应?您将如何改进它?
继续学习
想要了解更多有关不同提示工程概念的信息吗? 转至进阶学习的页面 查找有关此章节的其他重要资源。
前往第五章学习,我们将了解创建高级的提示工程技巧!